Es hora de instalar alguna que otra librería. Sin dudarlo un segundo arranca la seguidilla de composer require.
Escribes algo de código, realizas tus pruebas, todo listo para hacer un commit.
git add .
git commit -m "Initial commit"
Y de pronto… algo llama tu atención.
¿Por qué se están agregando dos archivos de composer?
Más específicamente, ¿por qué el composer.jsony el composer.lock?
¿Acaso el .lock no se genera automáticamente al ejecutar composer install?
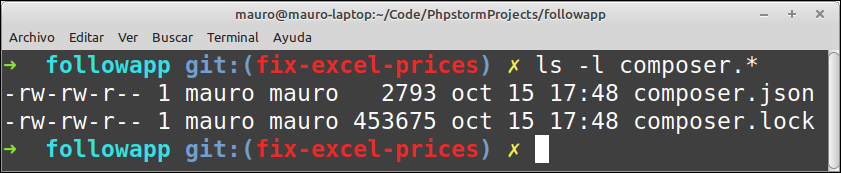
Es más, dando una rápida mirada se ve que el .lock pesa mucho más (¡muchísimo más!) que el .json:
¿Es realmente necesario engordar el repo con este archivo?
Respuesta corta: sí.
¿Querés saber por qué?
Te lo explico a continuación.
composer.json vs. composer.lock
Ambos archivos tienen formato json, así que, por este lado no pasa el tema.
¿Qué tiene composer.lock que no tenga composer.json?
Si abrís ambos archivos notarás que son parecidos, pero no iguales.
En principio, en el composer.json se almacenan los patrones de dependencias, mientras que en el composer.lock se almacenan las dependencias con sus versiones exactas (Más las dependencias de esas dependencias y otro montón de información).
En otras palabras, en el archivo composer.json se almacena la mínima información necesaria para generar el composer.lock
Ya sé, ya sé, todavía no respondí a la pregunta: si puedo generar el composer.lock a partir del composer.json… ¿para qué quiero comitear el primero?
La respuesta radica en el hecho de que un patrón de dependencias puede resolverse con muchas opciones diferentes.
Por ejemplo,
"doctrine/common": "^3.4"
Podría satisfacerse con doctrine/common en sus versiones :
3.4.0
3.4.1
3.4.2
3.4.3
3.4.4
3.4.5
Aunque no sería compatible con 3.3.* ni con 3.5.*.
El sistema de restricciones de versiones tiene sus vueltas pero si querés aprender más podés consultarlo directamente acá.
Y todo esto es importante porque…?
Porque, si hiciste tus pruebas con la versión x.y.z de una librería y luego, al momento de instalar la aplicación, sin que te des cuenta instalás la versión x.y.z+1 es posible que te encuentres con ese tipo de sorpresitas que a nadie le gustan.
De hecho, una de las razones más importantes que dieron origen a Composer es precisamente esta, asegurarte de que las versiones de las dependencias estén sincronizadas entre entornos.
Por eso el archivo se llama .lock, porque las dependencias están cerradas.
Así que, si pensabas ahorrarte algunos bytes en el repo… me temo que no estás de suerte en esta ocasión.
Cuando accedés usando el navegador todo funciona a las mil maravillas.
Está todo listo para ir a producción.
O casi.
Existen algunas pequeñas tareas que hay que hacer por fuera de la web. Limpiar archivos viejos… borrar las cuentas de usuario inactivas… lo típico, bah.
Si la URL a la que ingresás es http://localhost:8080… el host de la db ¿no debería ser localhost?
Probar no cuesta mucho… cambiás db por localhost y… ¡funciona!
Listo, vamos a producción.
mmm, mejor hacemos una última prueba del sitio, ¿no?
Boom. Error 500.
PHP Fatal error: Uncaught PDOException: SQLSTATE[HY000] [2002] No such file or directory in...
¿Cómo es posible? Si recién funcionaba…
¿Es que acaso es imposible hacer funcionar la web y el script de CLI sobre Docker?
No, claro que no.
Veámoslo paso a paso.
Qué pasa cuando se accede vía web
Cuando accedés a tu aplicación a través de la url http://localhost:8080, a pesar de que diga localhost, no es realmente tu computadora la que atiende esa petición (Bueno técnicamente sí lo es, pero a través de Docker).
El :8080 juega un papel muy importante.
Para que esto funcione, el puerto 8080 debe estar mapeado al puerto 80 del webserver que está corriendo en tu contenedor Docker.
Esto significa que, si bien tu computadora está escuchando a través del puerto 8080, lo que hace es re-enviar todo el tráfico recibido a través de él hacia el puerto 80 dentro del contenedor Docker configurado a tal efecto (Probablemente esto está definido en el archivo docker-compose.yml).
Distinto sería el caso si estuvieses usando el servidor incorporado a php (Es decir, si iniciaras tu aplicación vía php -S localhost:8080). En tal caso, la web y el CLI estarían usando el mismo entorno y, por lo tanto, no tendrías problemas.
Veamos ahora qué es lo que ocurre en el otro caso.
Qué pasa cuando se accede vía CLI
Lo primero que debés comprender es qué es exactamente lo que se ejecuta cuando hacés php my_script.php.
Ante todo, estás invocando al intérprete de php pasándole como argumento la cadena my_script.php.
Hasta aquí supongo que no hay nada muy novedoso, ¿cierto?
El problema comienza cuando tu script depende de configuraciones de entorno, como en este ejemplo.
Lo que ocurre es que, precisamente, el entorno de tu host es diferente del de los contenedores Docker. De eso se tratan los contenedores: de unidades de ejecución aisladas del host.
De hecho, Docker tiene su propio manejo de redes interno.
Esto quiere decir que el nombre db dentro del contenedor está asociado con una IP, mientras que fuera del entorno Docker no.
Cómo solucionar el problema
Ahora que tenés claro por dónde pasa el problema, la solución es ejectuar el script de PHP dentro del contenedor.
Tenés varias formas de hacerlo. Te comento rápidamente dos de ellas:
Con docker-compose
Si estás usando docker-compose podés ejecutar el siguiente comando:
docker-compose exec my_service php my_script.php
Suponiendo que el servicio donde está tu script está activo y se llama my_service, lo que verás en pantalla será el resultado de la ejecución de tu script.
Sin docker-compose
Si no usás docker-compose podés usar un comando del estilo de:
Este ejemplo es muy similar al de arriba. La principal diferencia es que en lugar de referirte a un servicio en ejecución, tenés que referirte directamente a un contenedor (my_container en este ejemplo) y tenés que montar los volúmenes en forma explícita.
Si el contenedor está corriendo el resultado que obtendrás será el mismo que el anterior.
Un pequeño consejo
Algo que puede ayudarte a evitar este tipo de situaciones es eliminar el php de tu host.
De esta forma, no vas a tener más opción que ejecutarlo dentro de Docker cuando así lo requieras.
Es cierto, es una opción algo extremista pero aún así puede resultarte útil ya que de esta forma siempre estarás seguro de que la versión de php que está utilizando tu script es exactamente la que esperás.
Me llegó esta pregunta que me pareció interesante compartir:
Estoy usando PHPStorm, y como sólo me pide el intérprete cuando trato de ejecutar en el navegador, todavía no lo he instaldo, quisiera saber si ya es mejor instalar el Xampp, si es recomendable y en caso de que no lo sea ¿por que?
Por si no sabés de qué se trata XAMPP, es un paquete que trae, todo lo que típicamente se requiere para desarrollar con PHP:
Necesitás trabajar con diferentes proyectos a la vez.
Son estos los momentos en te das cuenta que el salvavidas estaba hecho de plomo.
Cuál es el problema con XAMPP
La sencillez que aporta XAMPP lo hace la opción más difundida entre los desarrolladores menos experimentados. Pero esa sencillez tiene un costo.
El primero de los problemas es que, al ocultar la complejidad real que implica montar un servidor, se propicia el efecto «¡Te juro que en mi casa andaba!». Como no sabés realmente qué tenés instalado es difícil verificar que el hosting tenga lo mismo (Más detalle de qué es exactamente lo que deberías mirar acá).
El segundo de los problemas es que hace muy difícil trabajar en diferentes proyectos donde cada uno tiene requerimientos de infraestructura diferentes (Por ejemplo, versiones diferentes del intérprete de PHP).
Por supuesto que, si sos conciente de estas limitaciones y sabés trabajar con ellas XAMPP puede ser una opción aceptable.
Qué usar en lugar de XAMPP
Las opciones son varias, hay algunas mejores que XAMPP y otras peores:
En general, docker es la mejor opción cuando se trata de montar entornos locales ya que es muy simple luego llevarlos a producción y/o compartir con tu equipo.
Pero bueno, es cierto también que dominarlo no es una tarea muy sencilla.
Si recién estás empezando (Y quiero decir que apenas estás dando tus primeros pasos), está bien que uses XAMPP pero es importante que tengas la idea de migrar lo antes posible.
Vayamos a lo importante: ¿cómo tomaron la decisión de migrar a una versión más actualizada?
…la gente que instala los servidores sugirió ir a la última versión de PHP y Apache y Centos y postgresql pero no va
Bien, ahora está más claro.
Llegados a este punto estamos realmente en un problema: por un lado, el sitio tiene que seguir funcionando.
Por el otro, no podemos pedirle al hosting que habilite una versión de PHP que sabemos que es compatible con nuestro sistema.
¿Qué se puede hacer?
Lo mejor sería buscar una imagen de docker que tenga la versión que buscamos, instalarla en el servidor y seguir la vida como si tal cosa.
Si esa no es una posibilidad, habrá que hacerse a la idea de que la solución tomará algún tiempo… con todo lo que ello implica.
Saltarse versiones de php puede ser bastante arriesgado.
En este caso, ir de la 5.5 directo a la 8.1 implica dejar de lado una serie de cambios que se realizaron al intérprete a tavés de los años, algunos para hacerlo más eficiente y otros para quitarle funciones que ya pueden seguir soportándose.
El camino más seguro llegados a este punto sería ir bajando de versión del lado del hosting (8.1., 8.0, 7.4 y así) hasta llegar a una que, o bien sea compatible con el sistema, o sea la más antigua soportada por el proveedor.
Si se llega al primer escenario (Una versión superior a la que veníamos usando pero en la que el sistema funciona bien) perfecto, tema resuelto.
Si, en cambio, la versión más antigua con la que podemos contar no es compatible con el sistema, tenemos trabajo por delante.
Supongamos por tomar un ejemplo que la versión más baja que nos permite usar el proveedor es la 7.1.
Entre la versión 5.5 y la 7.1 hubo tres versiones intermedias (5.6, 7.0 y la propia 7.1).
La manera más segura de llegar de una versión de php a otra es pasar por todas las intermedias.
Antes de que me lo digas, sí, es un trabajo arduo y molesto, lo sé… pero me temo que es la posibilidad menos riesgosa, así que… más vale empezar a trabajar.
Lo que vas a necesitar es seguir este proceso:
Instalar en un ambiente de pruebas la versión a la que vas a intentar migrar (5.6 sería la primera en este caso)
Instalar y configurar el sistema en dicho ambiente de pruebas
Ejecutar las pruebas
Hacer los ajustes correspondientes al código
Pasar a la siguiente versión y volver al paso 1
Algunas herramientas que te van a ayudar
Existen algunas herramientas en las que te podés apoyar para hacer este proceso algo menos laborioso:
En general, migrar a una nueva versión de php no es precisamente una tarea sencilla pero si encima lo tenés que hacer a las apuradas… puede volverse una verdadera pesadilla.
Esto es algo que difícilmente puedas prevenir si estás en ambientes de hosting que no controlás.
Todo lo que querías era hacer una prueba sencilla. Como para comprobar por tus propios medios, si todo lo que te dijeron de Docker era realmente así y en cambio… tenés que ponerte a escribir archivos de texto inentendibles.
Te tengo buenas noticias: hay varias herramientas muy simples que podés usar para generar los dichosos Dockerfile.
Te presento algunas.
Devilbox
http://devilbox.org/ te permite crear un entorno moderno y altamente personalizado con soporte para LAMP sobre docker.
Su instalación es sencilla:
git clone https://github.com/cytopia/devilbox
cd devilbox
cp env-example .env
docker-compose up
Y listo.
En tus manos un LAMP con Redis, Memcached, MongoDB, phpMyAdmin y un montón de herramientas de administración disponibles en http://localhost para hacer todo bien fácil.
Ah, y claro, si querés ver qué hay detrás de la magia, el archivo docker-compose.yml está a tu disposición en el directorio donde clonaste el repo.
PHPDocker
https://phpdocker.io/ es un sitio donde podés, a través de un wizard, configurar la imagen Docker que querés generar:
Una vez tenés todo donde debe estar descargás el archivo comprimido, lo descomprimís en el directorio que más te guste, docker-compose up y, voilá, tu entorno php Dockerizado está disponible con todos los condimentos que hayas seleccionado.
Sail
Sail es una herramienta perteneciente al framework Laravel. Si creas una nueva aplicación desde cero no tendrás más que ejecutar ./vendor/bin/sail up dentro del directorio raíz de tu proyecto para comenzar.
Una vez descargado y configurado todo podrás entrar en http://localhost y disfrtuar de tu nuevo entorno de trabajo con Docker.
Y, como siempre, el archivo docker-compose.yml estará allí para investigar/modificar.
Y un par más…
Un par de herramientas más que vale la pena conocer son:
Deck: una aplicación de escritorio basada en electron.js con la que puedes crear un ambiente entero para desarrollo. La iba a incluir en este listado pero al probarla falló la instalación… tal vez más adelante cuando esté más madura la agregue.
El tema del código limpio está de moda, ¿no? Sí, pero también tiene sus fundamentos.
El código limpio es más comprensible y, por ende, mantenible en el tiempo.
Esto es especialmente importante cuando trabajas como parte de un equipo. Cuanto más claro sea el código, más fácil será para nuevos miembros hacerse productivos.
Todo el mundo está de acuerdo en esto pero lo cierto es que limpiar un código que lleva años acumulando capas de mugre puede ser una tarea titánica.
La respuesta más comúnmente usada ante estos escenarios es «¿para qué intentarlo cuando sé que no lo lograré?»
Cuando en realidad el escenario debería ser más parecido a:
Es decir: la opción de no limpiar no es realmente una opción… es cuestión de definir por dónde empezar.
Pero ahora, volviendo al código, hay algunas técnicas de limpieza más sencillas (¡y menos riesgosas!) que otras.
No es lo mismo cambiar el nombre de una variable que modificar la arquitectura.
Así que… vamos al punto. Mi enfoque para pasar de algo como esto:
<?php
declare(strict_types=1);
namespace GildedRose;
final class GildedRose
{
/**
* @param Item[] $items
*/
public function __construct(
private array $items
) {
}
public function updateQuality(): void
{
foreach ($this->items as $item) {
if ($item->name != 'Aged Brie' and $item->name != 'Backstage passes to a TAFKAL80ETC concert') {
if ($item->quality > 0) {
if ($item->name != 'Sulfuras, Hand of Ragnaros') {
$item->quality = $item->quality - 1;
}
}
} else {
if ($item->quality < 50) {
$item->quality = $item->quality + 1;
if ($item->name == 'Backstage passes to a TAFKAL80ETC concert') {
if ($item->sellIn < 11) {
if ($item->quality < 50) {
$item->quality = $item->quality + 1;
}
}
if ($item->sellIn < 6) {
if ($item->quality < 50) {
$item->quality = $item->quality + 1;
}
}
}
}
}
if ($item->name != 'Sulfuras, Hand of Ragnaros') {
$item->sellIn = $item->sellIn - 1;
}
if ($item->sellIn < 0) {
if ($item->name != 'Aged Brie') {
if ($item->name != 'Backstage passes to a TAFKAL80ETC concert') {
if ($item->quality > 0) {
if ($item->name != 'Sulfuras, Hand of Ragnaros') {
$item->quality = $item->quality - 1;
}
}
} else {
$item->quality = $item->quality - $item->quality;
}
} else {
if ($item->quality < 50) {
$item->quality = $item->quality + 1;
}
}
}
}
}
}
Consiste en ejecutar, casi mecánicamente, los siguientes pasos
1. Eliminar el hard-coding
Expresiones del tipo if ($item->quality < 50) { son bastante peligrosas. A priori surgen dos preguntas importantes:
¿Por qué 50 es un número especial?
¿Todos los 50 significan lo mismo?
En general, este tipo de números mágicos, tienen un sentido claro dentro del contexto de una aplicación. Probablemente cuando se escribió este código dicho contexto era claro pero, al no hacelo explícito, se hace muy complicado comprenderlo para alguien que lo ve por primera vez.
Una forma de evitar este problema es, simplemente, reemplazar este valor clavado por una constante de clase:
const MAX_ITEM_QUALITY = 50;
De esta forma se logra:
Dar significado a un número que a simple vista parece arbitrario
Permitir que si ese valor llega a cambiar en el futuro no sea necesario rastrear todos los lugares donde se usó el valor. Bastará con modificar la definición de la constante.
Lo mismo vale para valores tipo string como en el caso de $item->name != 'Backstage passes to a TAFKAL80ETC concert'
2. Extraer condicionales
El siguiente paso que suelo dar en este proceso es extrear las condiciones a métodos propios. Por ejemplo:
if ($item->name == 'Backstage passes to a TAFKAL80ETC concert') {
La idea es la misma. En lugar de, cada vez que se lea el código haya que concluir que el hecho de que name sea 'Backstage passes to a TAFKAL80ETC concert' significa que el ítem es un Backstage pass, dispongo de un método re-utilizable que me responde lo que realmente quiero saber.
Este ejemplo puede parecer trivial al comienzo, pero no lo es tanto.
¿Qué pasaría si, más adelante, la determinación del tipo de item viniese dada por alguna otra propiedad?
Este pequeño truco cobra todavía mayor importancia cuando las condiciones son complejas (cuando hay &&, || y/o muchos paréntesis)
3. Extraer cuerpo de loops
Del mismo modo, extraer los cuerpos de los bucles a métodos logra un resultado similar. Por un lado se reduce la complejidad del método y por otro se gana la posibilidad de re-utilizar la operación en diversos contextos.
En el ejemplo se hace muy visible el ciclo principal:
foreach ($this->items as $item) {
if ($item->name != 'Aged Brie' and $item->name != 'Backstage passes to a TAFKAL80ETC concert') {
if ($item->quality > 0) {
if ($item->name != 'Sulfuras, Hand of Ragnaros') {
$item->quality = $item->quality - 1;
}
}
} else {
if ($item->quality < 50) {
$item->quality = $item->quality + 1;
if ($item->name == 'Backstage passes to a TAFKAL80ETC concert') {
if ($item->sellIn < 11) {
if ($item->quality < 50) {
$item->quality = $item->quality + 1;
}
}
if ($item->sellIn < 6) {
if ($item->quality < 50) {
$item->quality = $item->quality + 1;
}
}
}
}
}
if ($item->name != 'Sulfuras, Hand of Ragnaros') {
$item->sellIn = $item->sellIn - 1;
}
if ($item->sellIn < 0) {
if ($item->name != 'Aged Brie') {
if ($item->name != 'Backstage passes to a TAFKAL80ETC concert') {
if ($item->quality > 0) {
if ($item->name != 'Sulfuras, Hand of Ragnaros') {
$item->quality = $item->quality - 1;
}
}
} else {
$item->quality = $item->quality - $item->quality;
}
} else {
if ($item->quality < 50) {
$item->quality = $item->quality + 1;
}
}
}
}
Que se reemplaza por:
public function updateQuality(): void { foreach ($this->items as $item) { $this->updateItem($item); } }
4. Eliminar cláusulas else
Siempre que sea posible, deberías preferir prescindir las cláusulas else en tu código.
Una forma de lograrlo es utilizar early return.
Por ejemplo:
public function canSeeMovie(Person $person): bool
{
if ($person->getAge() >= 18) {
...
} else {
return false;
}
}
Bien podría ser reemplazado por:
public function canSeeMovie(Person $person): bool
{
if ($person->getAge() < 18) {
return false;
}
...
}
Esto facilita mucho la lectura. Primero se ponen todas las validaciones o condiciones que podrían hacer que el método no pueda ejecutarse por completo y luego se codifica para el camino feliz.
Otro caso bastante parecido es el de usar valores por defecto:
public function getMaxSpeed(Car $car): int
{
if (in_array($car->getName(), ["Ferrari", "Porsche"])) {
$maxSpeed = 300;
} else {
$maxSpeed = 200;
}
return $maxSpeed;
}
Se transformaría en:
public function getMaxSpeed(Car $car): int
{
$maxSpeed = 200;
if (in_array($car->getName(), ["Ferrari", "Porsche"])) {
$maxSpeed = 300;
}
return $maxSpeed;
}
5. Eliminar variables temporales
Las variables temporales suelen crearse para aclarar cosas pero muchas veces su efecto es precisamente el contrario:
public function showMovieTo(Movie $movie, Person $person): void
{
$canSeeTheMovie = $this->canSeeMovie($person);
if ($canSeeTheMovie) {
$this->playMovie($movie);
}
}
En este pequeño ejemplo vemos que al llegar a la línea if ($canSeeTheMovie) { se necesita volver hacia atrás buscando la última asignación realizada a la variable $canSeeTheMovie para determinar qué hará este método.
Mucho más fácil de comprender es:
public function showMovieTo(Movie $movie, Person $person): void
{
if ($this->canSeeMovie($person)) {
$this->playMovie($movie);
}
}
Esta técnica no siempre es aplicable. En todo caso, lo segundo mejor por hacer es traer la definición y/o asignación de la variable lo más cerca de su uso que se pueda.
6. Renombrar, renombrar y renombrar
Este es un paso algo más sutil pero no menos importante.
El código que escribimos debe ser legible por humanos… muy probablemente por nosotros mismos en un futuro no muy lejano, de modo que es casi un deber moral escribirlo de un modo legible.
Encontrar buenos nombres para los elementos de nuestro código es una de las partes más complejas de programar, principalmente porque no hay recetas.
Algunos lineamientos que te puedo dar:
Escribir todo el código en inglés (No usar Spanglish)
No usar abreviaturas (Preferir $unusedTableNames a $utNm)
Poner nombres que revelen intención, no implementación (Prefereir $emptyAccounts sobre $emptyAccountsArray)
En el caso de clases o funciones, poner nombres que coincidan con el código.
Este último es, probablemente el punto más delicado. Durante la vida de un proyecto de software, es muy probable que un elemento cambie su definición conforme va pasando el tiempo.
Cuando eso sucede, es decir, cuando te toca modificar el código del cuerpo de un método (O de una clase en su totalidad), vale la pena preguntarte si el nombre que tenía antes de tu intervención sigue reflejando lo que el método hace (o lo que aporta mejor dicho) y, en caso de no ser así, es una buena idea darle un nuevo nombre más ligado a la realidad.
Y ahora… ¿qué?
Casi todos los cambios que nombré en este post se pueden realizar de forma bastante simple y segura utilizando un IDE, más adelante tocará encarar el refactor propiamente dicho:
Pero… antes de intentar avanzar por este camino hay que asegurarse de contar con buena covertura de tests.
Si te interesa este tema te recomiendo leer el libro de Código Limpio de Robert C. Martin.
Por último te animo a que practiques tus habilidades de refactoring con la kata Gilded Rose, de la que saqué el código que usé para el ejemplo principal.
El caso es que ambos códigos son funcionalmente equivalentes, de modo que… ¿qué es lo que está mal ahí?
El problema es que no se está utilizando un estándar de codificación.
Qué es un estándar de codificación
Un estándar de codificación es una serie de reglas que determinan cómo debe escribirse el código.
El objetivo es lograr un código fácil de leer por otros humanos (para la computadora mientras funcione todo lo demás da igual).
Un ejemplo de una regla como esta podría ser «todos los if llevan {} independientemente de que haya una línea dentro del bloque o más de una«.
Por qué es importante usar un estándar de codificación
Los estándares de codificación ayudan a disminuir el esfuerzo necesario para escribir el código: no se pierde tiempo tomando micro-decisiones como si poner o no poner las {} en cada situación.
A la vez, el uso de un estándar de codificación hace más fácil la lectura del código escrito por diferentes personas, lo que hace más sencillo el mantenimiento del código a largo plazo.
En definitiva, seguir un estándar de codificación permite disminuir la carga cognitiva que soportan los desarrolladores.
El estándar más ampliamente aceptado actualmente es PSR-12 pero es bastante común que cada organización cree su propio estándar, esperablemente basado en alguno pre-existente, lo cual suele derivar en una situación como la que bien ilustra este cómic de xkcd:
Cómo adaptar el código existente al estándar
Una vez se ha definido el estándar a utilizar, no suele ser complejo implementarlo en el código que se generará a partir del momento actual.
El desafío consiste en realizar las modificaciones requeridas al código pre-existente para que sea compatible con el estándar.
php-cs-fixer es una herramienta de línea de comandos escrita en php por Fabien Potencier y Dariusz Rumiński cuyo objetivo es, precisamente, el de modificar código de modo de garantizar que cumpla con las reglas definidas en un estándar de codificación.
Su uso es bastante simple, sólo requiere indicarle la ruta a la base de código sobre la que se trabajará y las reglas que se desea hacer cumplir.
Ejemplo de uso de php-cs-fixer
Partiendo de un código que no respeta el estándar PSR-12, usando este comando:
Donde puede verse qué archivos han sido modificados y qué regla se ha aplicado a cada uno.
Cómo especificar qué reglas aplicar en php-cs-fixer
Existen dos formas de especificar qué reglas se aplicarán en una corrida en particular:
Parámetros al momento de ejecutar el script
Mediante un archivo de configuración
Independientemente de cuál sea el método elegido, las reglas pueden ser especificadas en forma explícita (una por una) o bien usando conjuntos pre-definidos.
Las reglas y los conjuntos se diferencian porque los últimos tienen un nombre que comienza con @.
En mi caso estoy usando este archivo de configuración (.php-cs-fixer.dist.php):
Es muy común, en los comienzos de la carrera profesional, la adopción de malas prácticas.
En este sentido los desarrolladores de habla hispana tienen una desventaja respecto de sus pares angloparlantes.
Para los segundos palabras como if, for o while tienen sentido por sí mismas.
Los primeros en cambio requieren un esfuerzo extra para hacer la traducción, por pequeño que sea.
El hecho de que no contar con el inglés como lengua materna lleva muchas veces a plasmar las ideas utilizando el vocabulario que resulta natural.
Sin embargo, las palabras reservadas del lenguaje utilizado, en este caso PHP, están tomadas del inglés.
Es por eso que es muy común encontrar construcciones como esta en el código producido por programadores latinos:
if (!empty($usuariosRegistrados)) {
...
}
Este código no tendrá problemas en ser ejecutado, sin embargo, encierra varios inconvenientes no siempre detectables a simple vista.
Aumento de la carga cognitiva
Este tipo de estructuras fuerza al cerebro a hacer un esfuerzo de traducción (sea de Español a Inglés o viceversa) que, por pequeño que sea, afecta el rendimiento.
Este punto se hace evidente cuando se requiere que desarrolladores que no hablan Español tengan una participación activa en el proyecto.
Comprender código escrito por otras personas (O por nosotros mismos habiendo pasado un tiempo considerable) resulta difícil. Si a esa complejidad se le suma la falta de significado de los identificadores, la tarea se volverá realmente ardua, cuando no directamente imposible.
Basta pensar en un código como:
if (!empty($a) && $bxbhg > 50 ) {
...
}
Independientemente de la experiencia y conocimientos que se tengan sobre PHP, trabajar sobre este código no será sencillo, mucho menos placentero.
Imposibilidad de aprovechar el potencial de herramientas
Los entornos de desarrollo (IDEs) modernos, los frameworks y demás herramientas a menudo incorporan caractetísticas de generación de código en forma automática.
Por ejemplo, un framework de testing automatizado como phpUnit puede generar sus resultados de esta forma:
PHPUnit 9.5.10 by Sebastian Bergmann and contributors.
.. 2 / 2 (100%)
Time: 00:00.009, Memory: 6.00 MB
OK (2 tests, 2 assertions)
O de esta:
PHPUnit 9.5.10 by Sebastian Bergmann and contributors.
Calculator
✔ Add adds
Time: 00:00.004, Memory: 6.00 MB
OK (2 tests, 2 assertions)
Según los parámetros pasados en la invocación del ejecutable.
Claro que, para que esto tenga sentido, el nombre del método a ser probado debe tener algún significado como frase escrita en inglés.
En este caso sería:
<?php
declare(strict_types=1);
use PHPUnit\Framework\TestCase;
final class CalculatorTest extends TestCase
{
public function testAddAdds()
{
$sut = new Calculator();
$this->assertEquals(8, $sut->add(5, 3));
}
}
Entonces… ¿es necesario aprender inglés?
La respuesta depende en gran medida de los objetivos profesionales.
Para quien aspire a integrar equipos de desarrollo compuestos por profesionales de diversas nacionalidades, no dominar el inglés puede convertirse en un limitante importante.
Claro que un buen nivel de inglés no es suficiente para competir globalmente pero es un buen comienzo.
¿Tenés que desarrollar una aplicación que maneja fechas?
Tal vez un portal para reserva de turnos, o quizás algún sistema de membresías por tiempo limitado o por qué no un programa que le pregunte al visitante su fecha de nacimiento y le diga el signo del horóscopo chino al que pertenece.
Más allá de cuál sea el objetivo de la aplicación en algún lado vas a necesitar almacenar fechas.
Y ese lado será probablemente una base de datos relacional y, más aún, si estás usando PHP, seguramente sea MySQL.
Existen varias opciones que podrías usar para definir el tipo de datos del campo en cuestión y la decisión puede no ser trivial.
Usar un VARCHAR para almacenar un dato fecha
Si bien técnicamente podrías guardar una fecha en un campo de tipo VARCHAR (O cualquier otro tipo string), esto te hará difícil resolver algunos problemas como por ejemplo ordenar un set de resultados en función de la línea de tiempo.
Es decir, si una fecha es '2020-02-01' y la otra es '19000-02-01' el motor te dirá que la primera es posterior a la segunda.
Esto sucede porque, en lugar de tomar el valor como una fecha, se lo está tratando como una simple cadena de caracteres y, por lo tanto, se está aplicando el orden lexicográfico.
Esto significa que para comparar se están tomando los caracteres y se comparan uno a uno, de este modo:
2
0
2
0
–
0
2
–
0
1
1
9
0
0
0
–
0
2
–
0
1
Por otra parte, como se trata de cadenas, el motor no será capaz de determinar que '2020-13-35' no es un valor aceptable.
Así que… no te lo recomiendo
Usar un TIMESTAMP para almacenar un dato fecha
Un segundo tipo de datos que podrías usar para guardar fechas es el TIMESTAMP.
Este seguramente va a funcionar mejor que el VARCHAR, pero tampoco es el ideal.
El TIMESTAMP es, internamente, un número muy grande que mide cuántos segundos pasaron desde segundo uno de UNIX (1970-01-01 00:00:01).
Usualmente este tipo de datos se utiliza para operaciones que requieren altísima precisión, como procesos de tiempo real… un poco exagerado cuando se quiere saber la fecha en que una persona recibió su último aumento de sueldo, ¿no?
Usar un DATE para almacenar un dato fecha
La mejor opción es usar un campo de tipo DATE.
Este tipo de datos modela una fecha mediante una estructura que tiene separados los componentes del mes, día y año.
Si bien al momento de visualizarlo no será distinguible de un VARCHAR que tenga el mismo contenido, a nivel funcional será muy diferente.
Entre otras, el tener los datos almacenados usando el tipo correcto permitirá realizar consultas como:
SELECT * FROM usuarios WHERE subscription_date BETWEEN '2020-01-10' AND '2020-01-20';
Y obtener como resultado aquellos usuarios que se han suscrito a nuestro sitio entre el 10 y el 20 de Enero de 2020.
Usar un DATETIME para almacenar un dato fecha
Si necesitas almacenar, además de la fecha, la hora exacta en que sucedió algo, lo mejor es utilizar el tipo de datos DATETIME que se comporta igual que DATE pero agregando la información de horas, minutos y segundos.
Empecé a responderle a su mensaje pero luego se me ocurrió que sería mejor aprovechar y contestarlo en público así que aquí voy.
Empecemos por comprender de qué se trata cada uno.
Qué es una clase abstracta
En su definición más cruda una clase se dice abstracta si no es posible utilizarla para crear objetos (instancias).
Suena un poco raro, ¿no? ¿Para qué quiero tener una clase si no es para crear instancias?
La explicación viene asociada al concepto de Herencia (Tema para otro artículo en todo caso).
Una clase abstracta puede usarse como base de una jerarquía.
Se define de esta forma:
<?php
abstract class Abstracta
{
public function metodoConcreto()
{
return true;
}
abstract public function metodoAbstracto();
}
Notá cómo el método metodoConcreto() tiene definición (está el cuerpo completo) y como en cambio, de metodoAbstracto() sólo está su declaración (Aparte de llevar la palabra «abstract» como modificador).
Para usarla en una clase concreta se necesita que la hija complete las definiciones que su padre (o alguno de sus ancestros) han dejado inconclusas:
class Concreta extends Abstracta
{
public function metodoAbstracto()
{
return true;
}
}
En la vida real, este tipo de estructura viene muy bien para implementar, por ejemplo, hooks.
La idea será algo como esto: la clase padre (abstracta) define una serie de operaciones bastante complejas y repetitivas y deja una o dos funciones sin definir para que la clase hija escriba aquí sus particularidades.
Un ejemplo que me viene a la mente es un ORM basado en ActiveRecord.
En este caso, habría una clase Record que tendría un método save y podría tener algún método tipo preSave/postSave para que cada tipo de registro en particular pueda intercalar validaciones u operaciones encadenadas.
Qué es una interface
Una interface puede definirse como una declaración de métodos abstractos.
En este sentido se parece a una clase abstracta… la diferencia (a simple vista al menos) es que una interface no puede definir métodos (Sólo puede declararlos).
Se ve de esta forma:
interface UnaInterface
{
public function f1();
public function f2();
}
Según los teóricos más puristas de la Programación Orientada a Objetos toda clase debería implementar al menos una interface.
Por lo general se utilizan interfaces cuando se quiere unificar nombres de métodos pero seguir manteniendo comportamientos que no tienen nada que ver uno con el otro.
De hecho, las interfaces suelen utilizarse como factor común entre clases que no pertenencen a una misma jerarquía.
Por ejemplo, si tomamos una clase Book y otra clase Invoice sería difícil establecer una relación jerárquica entre ellas (Ni Book es un tipo especial de Invoice ni viceversa).
Sin embargo, es muy probable que ambas clases se beneficien de contar con un método print, aunque la forma específica de responder a esa llamada (Es decir, la forma de imprimir) será muy diferente para cada uno de ellos.
Habiendo clases abstractas… ¿por qué se necesitan interfaces?
La respuesta a esta pregunta tiene que ver con algunos problemas de implementación.
En algunos lenguajes (C++ por ejemplo) existe lo que se conoce como Herencia Múltiple (La posibilidad de que una clase tenga más de un antecesor directo).
Es decir, el esquema se vería algo como:
Se ve que la clase TA hereda de Student Y de Faculty. Hasta ahí no hay problema… pero ¿qué pasa si Student define un método con el mismo nombre que Faculty?
Cuando se invoque $ta->metodo() ¿cuál debería ejecutarse? (asumiendo por supuesto que TA no tiene una definición propia de ese método).
Una forma elegante de resolver este problema es impedir la herencia múltiple (Eso es lo que hacen, entre otros, Java y PHP).
Pero la necesidad de reutilizar nombres (y comportamientos) a lo largo de diferentes jerarquías de clases no desaparece… de ahí surge la idea de las interfaces (y los traits… tema para otro artículo).
Un punto importante: una clase (en PHP al menos) puede implementar tantas interfaces como se desee (pero sólo puede extender una clase base).
Cómo decidir si conviene una clase abstracta o una interface
Pues bien, ahora sí estamos listos para responder a la pregunta original 🙂
Esto parece una obviedad, pero no es tan así… a veces nos encontramos con objetos que parecen estar relacionados mediante herencia pero en realidad no es así.
Para determinar si este es el caso vale preguntarse: «¿Es este objeto un caso particular de sus predecesores?» (Un auto es un vehículo).
El uso de interfaces nos permite «olvidar» momentáneamente con qué tipo de objetos estoy trabajando.
En esto se basa el principio de segregación de la interface (La I de SOLID)
Un ejemplo que me viene a la mente es algo que utilizamos hace unos años para una red social de viajes en la que trabajaba.
Originalmente esta red social permitía a sus usuarios subir sus fotos y diarios de viaje (compartir sus experiencias en formato similar a un blog).
Una foto y un diario de viaje tenían bastante pocas similitudes (De hecho las clases que las representaban no tenían ningún ancestro en común).
Un día surgió la necesidad de dotar al sistema de la posibilidad de que otros usuarios dejaran sus opiniones sobre las fotos y/o los diarios de los demás.
Entonces se nos ocurrió agregarle a la clase usuario un método opinar().
Pero no podíamos crear un método opinarSobreFoto( Foto $foto ) y otro opinarSobreDiario( Diario $diario )… en rigor de verdad podríamos haberlo hecho pero no era para nada mantenible.
Una forma mejor de resolverlo fue crear una interface Opinable que tanto la clase Foto como la clase Diario implementaran y luego el método Usuario::opinar pudiera usar, dando lugar a algo como:
<?php
class Usuario
{
public function opinar( Opinable $opinable, string $texto )
{
return new Opinion( $opinable, $this, $texto );
}
}
De esta forma, agregar otro opinable (Por ejemplo, un destino visitado) no supone ningún problema para la clase Usuario.