Una pregunta que parece algo obvia, ¿no? Lo que se necesita para poner en línea una aplicación PHP es un hosting. No hay mucho más que decir al respecto, ¿cierto? Pues… tal vez convenga hilar un poco más fino.
Si bien en sus inicios PHP se utilizaba exclusivamente para la creación de aplicaciones web, hoy en día abarca un abanico mucho más amplio.
En este artículo me centraré en la infraestructura mínima necesaria para poner en línea una aplicación web desarrollada con PHP.
Qué debe tener un servidor para hostear una aplicación PHP
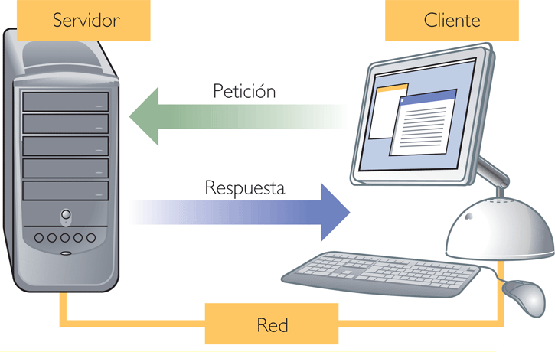
Lo primero que debemos comprender es que, para que una aplicación web esté en línea, independientemente del lenguaje en que esté desarrollada, se requiere:
- Que el código esté disponible en alguna computadora conectada a Internet (El Servidor)
- Que dicha computadora cuente con algún software capaz de recibir peticiones a través de Internet (El WebServer) instalado y funcionando
- Que la dirección IP de esa computadora sea conocida en forma pública (o fácilmente averiguable)
En el caso de PHP un requisito adicional es que esté presente en el servidor un software capaz de interpretar y ejecutar el código (El intérprete).
Existen muchas combinaciones diferentes de software que se encargan de esto, entre las más conocidas podemos encontrar:
Incluso es posible utilizar el Internet Information Server si el sistema operativo del servidor es Windows.
Luego será necesario configurar el servidor web de modo que ciertas peticiones sean derivadas al intérprete de php (A diferencia de otras que simplemente deben ser servidas enviando el contenido de los archivos solicitados).
Esta configuración es diferente según el paquete de software con que se cuente.
Qué servicios aparte del hosting se necesitan para poner online una aplicación PHP
Usualmente, cuando se desea poner un sitio en línea, se busca que los visitantes accedan al mismo a través de una dirección sencilla de recordar (Lo que se conoce como un dominio), sin embargo, para que la computadora cliente pueda conectarse a la computadora servidor es necesario conocer su dirección IP.
Para ello existe un servicio adicional: el DNS.
De modo que, para que nuestro sitio esté disponible al público será necesario, además de registrar un dominio, configurar el DNS para que realice esa traducción.
Luego, dependiendo de las necesidades específicas del sitio que queremos montar, es probable que sea necesaria la instalación de algún software de gestión de bases de datos (Como MySQL, PostGre o alguno similar).
Respecto de la computadora que actuará como servidor, existen diferentes opciones (de diferentes costos y requisitos técnicos).
Se puede usar una computadora personal propia, contratar espacio en un servidor compartido, comprar una computadora y dejarla en un proveedor que garantice la alimentación y conectividad, usar un servidor virtual… en fin, las opciones son muchas.
¿Te cuesta decidir? Este post puede ayudarte.