
Hace un tiempo, cuando trabajaba para una gran .com del rubro turismo, surgió un escenario muy interesante que teníamos que resolver junto con mi equipo:
Teníamos un servidor de bases de datos que daba soporte a siete servidores que hacían de FrontEnd. Nuestra aplicación era php puro (con un «framework» desarrollado in-house… muy mala idea) y todos los frontends corrían el mismo código (Todo detrás de un balanceador de carga, obvio):
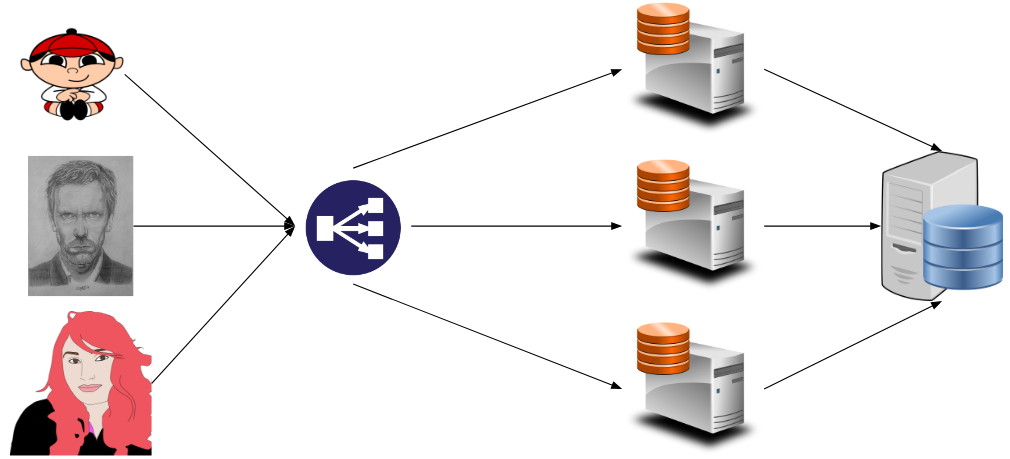
El problema que teníamos era que el sitio tenía bastante tráfico y la base de datos se nos convertía en un cuello de botella bastante a menudo.
La solución que implementamos consistía en tener ciertas partes de las respuestas pre-calculadas.
Ahora, como te imaginarás, mantener una experiencia de navegación consistente teniendo varios servidores diferentes tiene sus complicaciones, en nuestro caso, el desafío más importante era cómo mantener copias sincronizadas de la información pre-calculada (Para evitar, por ejemplo, que un simple F5 mostrara algo diferente de una página supuestamente estática).
Por otro lado, los servidores de FrontEnd que usábamos eran simples instancias de máquinas virtuales que (no estoy muy seguro de por qué), tenían una tendencia a romperse intempestivamente (Bueno… un poco por eso teníamos tanta redundancia :)), con lo cual, no era viable tener un único responsable de la generación del caché…
Lo que necesitábamos básicamente era una arquitectura que permitiera:
- Que cualquier FrontEnd fuera capaz de generar la versión estática de la información
- Que no hubiese dos FrontEnds generando la versión estática a la vez
- Que todos los FrontEnds sirvieran el mismo contenido (Si estaba disponible)
Sin entrar en detalles sobre cómo logramos el objetivo 2 (Lo dejo para otro post en todo caso, pero involucra un sistema de semáforos), lo que hicimos fue crear una función (Método de una clase en realidad) que recibiera dos funciones:
- Una para verificar si la copia local de la información estaba vigente aún
- Otra para generar la información en caso de ser necesario
Lo interesante de este mecanismo es que, gracias al uso de los callbacks fue bastante sencillo separar (¡y reutilizar!) el mecanismo de exclusión mutua y todo lo que hacía al andamiaje de lo que tenía que ver con la generación de la información propiamente dicha.
Una versión simplificada del código a modo de ilustración es esta:
public function get( $sKey, $iTtl, Closure $fGeneration, array $aGenerationParams = [], Closure $fValidation = null ) {
$oRemoteStorage = $this->getRemoteStorageFactory()->build($sKey);
if ( ( $oCache = $this->getFromStorage( $oRemoteStorage ) ) && !$oCache->isExpired() && $fValidation( $mContents = $oCache->getContents() ) ) {
$this->putInStorage( $oCache, $oLocalStorage );
return $mContents;
}
$mContents = call_user_func_array( $fGeneration, $aGenerationParams );
$oCache = new CacheObject( $mContents, time() + $iTtl );
$this->putInStorage( $oCache, $oLocalStorage );
$this->putInStorage( $oCache, $oRemoteStorage );
return $mContents;
}
Lo interesante de esta función son los parámetros $fGeneration y $fValidation, ambos Closures, esta es la clave para que el mecanismo de caché se mantenga agnóstico respecto de qué es exactamente lo que se está cacheando… cómo se genera ese caché y cómo se verifica su vigencia son problemas del usuario del mecanismo de caché.
De esta forma queda un sistema altamente reutilizable :).
Si te interesa ver el código completo (Está un poco viejo, pero la idea sirve), acá está el repo en GitHub.
¿Te quedó alguna duda? Publica aca tu pregunta