Hace un tiempo, trabajando para una red social de viajes, me topé con un desafío sumamente interesante: adaptar un sistema hecho para trabajar exclusivamente en Español para dar soporte a varios idiomas (En particular, en nuestro caso se trataba de la versión en Portugués, pero se preveía que podríamos necesitar más idiomas en el futuro).
Si el sistema se arrancara desde cero no sería un gran problema. Se podría usar Symfony o algún otro framework similar que ya tienen incorporada la funcionalidad multi-idioma y listo.
Desafortunadamente, en aquel momento el sistema estaba desarrollado sobre un framework propietario y la re-escritura estaba fuera de discusión.
Así que, junto a mi equipo de desarrollo, comenzamos a pensar cómo resolver este problema.
Lo primero que entendimos fue que teníamos que resolver dos desafíos complementarios:
- La internacionalización del contenido estático (Contenido generado por nosotros mismos, botones, menúes, etc…)
- La internacionalización del contenido dinámico (Contenido subido por los propios usuarios)
Cómo internacionalizar el contenido estático de un sitio
En nuestro caso, dado que la aplicación era grande, había mucho contenido con textos hardcodeados.
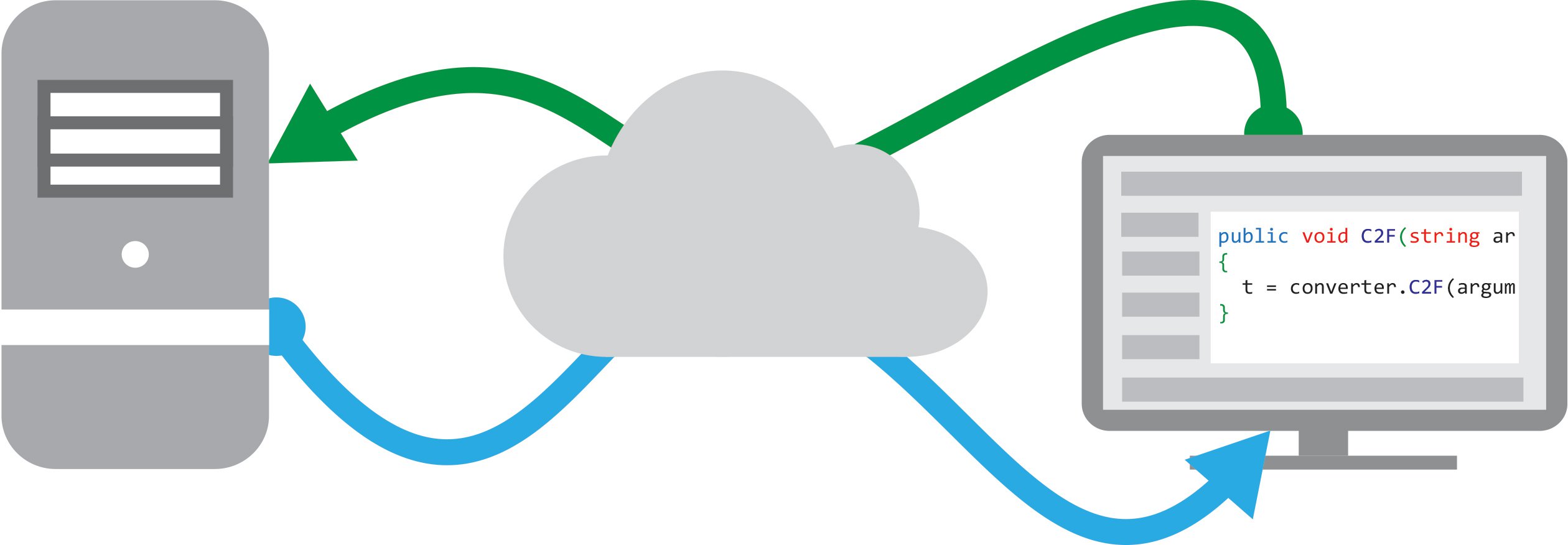
Decidimos utilizar gettext como motor de traducción (Tenía la ventaja de usar archivos .po y .mo, lo cual hacía muy fácil el proceso de traducción).
El siguiente paso era el más pesado: generar los archivos con los textos a traducir.
En aquel momento usábamos el motor de templates Smarty (Hoy no dudaría un segundo en usar Twig), así que el camino por delante (Si bien sumamente tedioso) era claro: había que crear una pequeña extensión para Smarty que permitiera tomar un texto y devolverlo traducido.
Y así lo hicimos (bueno, contratamos a alguien para que lo haga :p).
Cómo internacionalizar el dinámico estático de un sitio
Claro que la traducción del contenido estático era sólo el comienzo… el verdadero desafío era traducir el contenido dinámico (o lo más parecido que se pudiera).
Decidimos utilizar un sistema de tags donde cada pieza de contenido (artículo, opinión, comentario, etc…) estuviera taggeado con el idioma en el que había sido escrito.
Cada usuario tenía un idioma asociado (lo poníamos por default según el idioma de su país y el usuario después podía modificarlo) y, cada vez que generaba un contenido se asumía que lo hacía en su idioma (Después los administradores del sitio podían re-taggearlo para corregirlo si lo consideraban necesario).
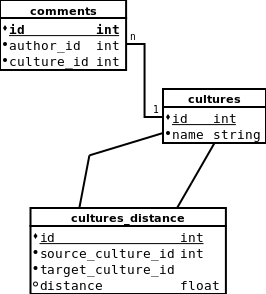
En definitiva era simple: una tabla idioma con un id y un nombre y en cada tabla de contenido una nueva columna para la clave foránea.
Y funcionó bien… hasta que dejó de hacerlo :p
¡Ojo! ¡No fue un problema técnico! De hecho, casi diría que el sistema funcionó demasiado bien.
¿Qué pasó?
La definición original desde el negocio era que cada visitante viera sólo contenido en su idioma, pero, cuando se iba a lanzar el sitio en portugués rápidamente nos dimos cuenta de que iba a arrancar vacío (Obvio, ¡no había ningún contenido taggeado en portugués!) y eso no iba a ser muy atractivo para los nuevos visitantes (ni para el SEO).
Así que cambió la directiva por algo mucho más sensato: no filtrar el contenido según el idioma del usuario si no priorizarlo (Es decir: para un usuario de habla portuguesa, primero se debía ver contenido en Portugués pero, una vez finalizado, se debía comenzar a ver contenido en Español).
Claro que eso estaba muy bien desde el punto de vista de los usuarios, pero… ¿quién piensa en los pobres programadores que tienen que implementar esa locura?
Pues bien, la solución que encontramos fue incorporar una noción de distancia entre idiomas.
La idea era que cada idioma (cultura en realidad porque también manejábamos variaciones regionales pero eso no cambia mucho así que no voy a complicar más de lo necesario por ahora).
De modo que la base de datos se veía más o menos así:
Esta estructura permite generar efectivamente una matriz donde cada cultura se relaciona con todas las demás:
| es | es_AR | pt_BR |
| es | 0 | 1 | 2 |
| es_AR | 1 | 0 | 2 |
| pt_BR | 2 | 2 | 0 |
Los números que están en el cruce de la matriz constituyen la distancia entre un idioma y el otro.
Esto sirve como criterio de ordenamiento, de modo que, cuando queremos mostrar los comentarios haríamos algo así como:
SELECT * FROM comments co INNER JOIN cultures_distances cd ON co.culture_id = cd.target_culture_id
WHERE cd.source_culture_id = ??
ORDER BY cd.distance
El placeholder se reemplaza por el id de la cultura del visitante actual, de modo que los contenidos están ordenados en función de la distancia existente entre el idioma del visitante y aquel en el que están escritos… no está mal, ¿cierto? 🙂
Este sistema a su vez, permite siempre meter más variaciones regionales entre medio (Basta con que la distancia sea un número real, o sea un float).
Otro punto que vale la pena explicar es que la distancia no tiene por qué ser simétrica (No necesariamente debe valer lo mismo la distancia entre «es» y «es_AR» que viceversa).
Siendo que no estamos hablando de temas de geometría si no de idiomas, podemos hacer lo que queramos (al fin de cuentas, ¡es nuestro sistema!).
Y bueno, así fue como funcionó nuestro sitio multilingüe.
Insisto en lo que decía al comienzo, si tenés la posibilidad, partí de un framework que soporte i18n… si no es el caso, espero este artículo te haya sido inspirador 🙂