PHPUnit, al igual que la mayoría de los frameworks de testing, se basa fuertemente en el supuesto de que la aplicación a verificar está desarrollada bajo el paradigma de Orientación a Objetos.
Sin embargo, es muy común en nuestros días encontrarnos con aplicaciones tipo spaghetti… ¿es posible hacer testing automatizado sobre ellas?
La respuesta es sí.
Claro que las respuestas a qué testear y cómo testear son un poco diferentes.
Qué puede testearse en una aplicación que no usa objetos
Obviamente, no será posible verificar una clase porque… la aplicación no tiene clases.
De modo que podemos testear:
La página que se presentará al usuario (Lo que podríamos asemejar a un test funcional)
El resultado de ejecutar alguna función en particular
El resultado de correr algún script
Cómo testear el resultado de una página php
Para este escenario nos tendremos que valer de un pequeño truco: las funciones ob_start y ob_get_clean (Además de tener instalado phpUnit, claro).
La idea es muy simple en realidad.
Se crea un caso de test, se abre un buffer y se incluye el archivo que queremos validar.
A continuación se levantan los contenidos del buffer y se examinan usando assertions.
Veamos un ejemplo simple:
El archivo que queremos validar se llama wrong.php
<?php
use PHPUnit\Framework\TestCase;
class PageTest extends TestCase
{
public function testGreeting()
{
ob_start();
require_once 'wrong.php';
$this->assertRegExp('/<p>Hello World!<\/p>/', ob_get_clean());
}
}
Para correr el test usamos el comando vendor/bin/phpunit PageTest.php y la salida será:
PHPUnit 9.3.7 by Sebastian Bergmann and contributors.
F 1 / 1 (100%)
Time: 00:00.004, Memory: 4.00 MB
There was 1 failure:
1) PageTest::testGreeting
Failed asserting that '<html>\n
<body>\n
<p>Bye bye world</p>\n
</body>\n
</html>\n
' matches PCRE pattern "/<p>Hello World!<\/p>/".
/home/mauro/Code/testing/PageTest.php:11
FAILURES!
Tests: 1, Assertions: 1, Failures: 1.
Cómo testear el resultado de una función php
Este caso es bastante similar al anterior, aunque un poco más simple.
Aquí lo que haremos será, en lugar de validar la salida completa, verificaremos qué sucedió como resultado de ejecutar la función.
Empecemos por modificar el archivo a testear:
<?php
function duplicate(int $p) : int
{
return $p * 3;
}
Y ahora hagamos un nuevo test:
<?php
use PHPUnit\Framework\TestCase;
class FunctionTest extends TestCase
{
public function testFunction()
{
ob_start();
require_once 'wrong.php';
$this->assertEquals(4, duplicate(2));
}
}
El resto sigue igual al caso anterior
Cómo testear la ejecución de un script php
Por último, podríamos requerir testear el funcionamiento de un script de línea de comandos (Un cronjob por ejemplo).
Imaginemos un script como este:
<?php
echo 'Bye bye '.$argv[1].'!';
Y este test:
<?php
use PHPUnit\Framework\TestCase;
class ScriptTest extends TestCase
{
public function testGreeting()
{
$this->assertEquals('Hello World!', shell_exec('php script.php World'));
}
}
Nos dará este resultado:
PHPUnit 9.3.7 by Sebastian Bergmann and contributors.
F 1 / 1 (100%)
Time: 00:00.026, Memory: 4.00 MB
There was 1 failure:
1) ScriptTest::testGreeting
Failed asserting that two strings are equal.
--- Expected
+++ Actual
@@ @@
-'Hello World!'
+'Bye bye World!'
/home/mauro/Code/testing/ScriptTest.php:9
FAILURES!
Tests: 1, Assertions: 1, Failures: 1.
Conclusión
En defintiva, no es cierto que es imposible testear aplicaciones php que no se basen en POO… lo que sí es cierto es que los tests van a ser más engorrosos y menos informativos.
Claro que eso es consecuencia de un diseño poco modular de la aplicación que estamos testeando… ¡pero esa fue precisamente la premisa del ejercicio!
Espero te haya dado alguna idea nueva, ¡espero tus comentarios!
A partir de aquí, todos los correos salientes serán recibidos por un único destinatario independientemente de quién sea el «verdadero».
Testear emails usando un servidor SMTP local
Otra forma de realizar estas pruebas es instalar un servidor SMTP local y configurarlo de modo de no realizar ningún envío, si no encolarlos todos y luego consultar los envíos pendientes.
Realizar esta configuración desde cero puede resultar bastante engorroso.
Afortunadamente existen algunas herramientas que simplifican mucho todo este proceso.
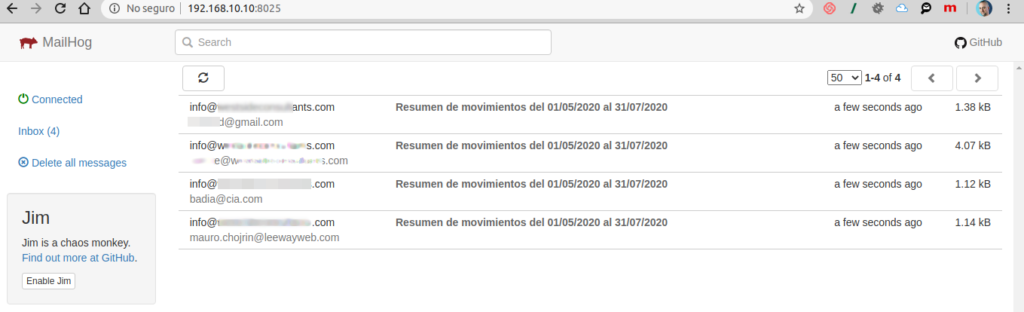
Una que me parece particularmente interesante es MailHog.
Es bastante simple de instalar y cuenta con una interface web para consultar los correos que se han «enviado» a través de ella:
El framework Symfony es de lo mejorcito que tenemos en el mundillo de PHP (Personalmente es mi favorito por lejos).
Para procesar un request se requiere un método de alguna clase (Un controlador).
Para decidir cuál es el controlador al que se debe invocar al momento de responder al pedido de un usuario se utiliza un componente llamado Router.
Este componente conoce el mapeo entre una URI y dicho controlador.
Existen diversos modos de definir este mapeo (por ejemplo mediante annotations).
Esto hace que, si una aplicación es grande, puede ser algo complejo encontrar cuál es exactamente el controlador que se esconde detrás de una URL.
En este artículo te mostraré un pequeño truco para obtener esa información.
Voy a asumir que estás en algún tipo de consola POSIX (Linux, BSD, Mac o algo como el WSL de Windows).
Cómo debugear el mapa de ruteo de Symfony
Algo que seguramente conoces si usas Symfony es el poderoso comando (¿o debería llamarle meta-comando?) console.
A través de esta interface es posible realizar una gran cantidad de tareas (e incluso implementar las tuyas).
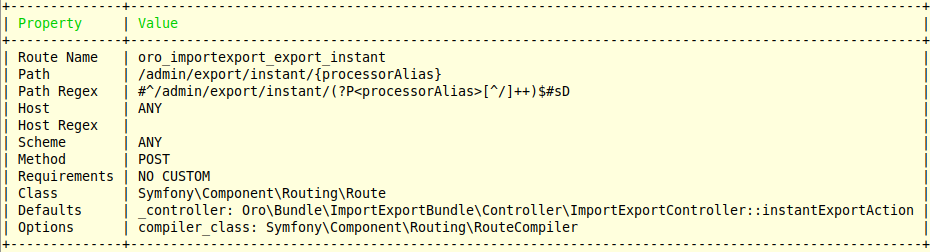
En esta ocasión quiero mostrarte un uso algo poco frecuente: el comando debug:router.
Usando este comando puedes ver un listado completo de las rutas definidas en tu proyecto, sin importar si están definidas usando YAML, XML, PHP o annotations.
Particularmente, si necesitas conocer la ruta que corresponde con una URL puedes usar la herramienta grep y un pipe, de esta forma:
Cómo encontrar el archivo donde está definido un controlador Symfony
Y ahora que sabes cuál es el controlador es fácil llegar al archivo que lo define… ¿cierto? Pues… depende.
Como decía, en el supuesto de una aplicación de mediana o gran envergadura, es probable que estés utilizando muchos bundles, con lo cual el controlador puede estar definido en varios lugares.
Una forma simple de llegar a este dato es usar el comando find, por ejemplo:
find vendor -type f -name ImportExportController.php
Y ahora sí, combinando esta información con la obtenida en el comando anterior es posible ver el código exacto del método que responde a esta petición.
Nota al pié: este último paso puede simplificarse mucho si utilizas algún buen IDE para PHP 😉
Se trata de un problema de optimización de consultas a una base de datos.
Imagina que tienes una base de datos con dos tablas:
Users
PhoneNumbers
Donde cada usuario puede tener muchos números telefónicos (Relación 1:N).
Ahora, imagina que tienes que mostrar un listado de todos los usuarios junto con sus números de teléfono.
Una forma de resolverlo sería utilizar una consulta tipo:
SELECT * FROM users;
Y luego:
foreach ($users as $user) {
$sql = "SELECT * FROM phone_numbers WHERE user_id = {$user->getId()};";
...
}
Lo que sucede aquí es que realizamos una consulta para obtener todos los usuarios y luego, una más por cada uno.
De ahí que el número total de consultas que se realizan es N (Número de usuarios) + 1.
Esto puede representar un gran problema cuando N es grande… especialmente cuando el tiempo que tarda cada consulta es significativo (Por ejemplo porque la base de datos está en un servidor remoto y hay que contar con los tiempos de transferencia de red).
Solución basada en JOIN
Una primera solución sería utilizar un join:
SELECT * FROM users u INNER JOIN phone_numbers p ON p.user_id = u.id;
Aquí el problema es que el resultado tendrá mucha información duplicada (Todos los datos del usuario estarán repetidos en cada fila), lo cual puede traernos inconvenientes con la memoria.
Solución de dos consultas
Una solución más eficiente se basa en la realización de dos consultas.
Los pasos son los siguientes:
Buscar los objetos principales
Obtener los Ids de dichos objetos
Buscar los objetos relacionados para aquellos Ids obtenidos en 2
Mostrar el resultado combinado
SELECT * FROM user;
$ids = array_map(function(User $u) { return $u->getId(); }, $users );
$phone_numbers = $db->query("SELECT * FROM phone_numbers WHERE user_id IN ('.implode(', ', $ids).')");
foreach ( $users as $user ) {
$str = $user->getName() . implode(',', array_filter($phone_numbers, function($p) use ($user) {
return $p['user_id'] == $user->getId();
}));
}
En esta solución la cantidad de consultas realizadas siempre es fija: 2.
Puede parecer algo más laborioso del lado del PHP, pero ten en cuenta que los tiempos de procesamiento siempre son significativamente inferiores respecto de los de comunicación vía red u otro tipo de operaciones de entrada/salida, con lo cual, vale la pena el esfuerzo extra 😉
La estructura de datos más utilizada en PHP es, por lejos, el arreglo.
Esto se debe a que la implementación de ellos es extremadamente flexible.
Un problema común que nos encontramos es el ordenarlos.
Cuando los arreglos son de una única dimensión no hay mucho problema, basta una función como sort, pero cuando el arreglo es una matriz las cosas son un poco más complejas ya que pueden existir diferentes criterios de ordenamiento.
El resultado será diferente si queremos ordenar por age que por name
Claro que podrías usar una solución diseñada por tí mismo basada en un par de ciclos anidados y seguramente funcionaría, pero sería trabajar de más.
Ordenar un arreglo PHP según un criterio propio
Una función muy útil para resolver este tipo de situación es usort.
Esta función recibe un arreglo como parámetro y una función que se utiliza para comparar cualquier par de elementos entre sí (Lo que se conoce como un callback).
De este modo, para el ejemplo anterior podríamos definir dos funciones de comparación:
Y como no puedo negarme a un pedido semejante, aquí estoy 🙂
Este va a ser un post algo atípico ya que el protagonista no será, como acostumbro, PHP si no JavaScript, por una razón sencilla: la acción más importante sucederá del lado del cliente y no del servidor.
Voy a hacer una aplicación del estilo prueba de concepto, es decir, van a quedar unos cuantos «cabos sueltos» pero la idea es que comprendas el principio detrás de esto.
El escenario que planteo es el siguiente:
Existe una base de datos en el servidor y muchos clientes interactuando con ella a la vez.
Un ejemplo real de esto es una aplicación tipo Google Docs o tal vez un juego online multi-jugador (Acá sólo me queda imaginar porque no tengo mucha experiencia en este área :p).
Pues bien, un modo de encarar este problema pensando en conexiones poco confiables es utilizar un esquema tipo event sourcing donde, en lugar de almacenar el estado actual de los objetos guardamos la secuencia de eventos que conducen a que las cosas sean como las vemos.
De este modo, cada cliente enviará al servidor sus novedades, el servidor las recibirá y las re-distribuirá a los demás y dejará en manos de cada cliente refrescar la vista.
Un problema que deberemos resolver es el de la sincronización: el orden en que sucedieron los eventos es importante y los relojes de cada uno de los clientes pueden estar des-sincronizados con lo cual no serán suficientemente confiables.
La solución que yo elegí es tomar la hora del servidor como base y que cada cliente marque los tiempos como la cantidad de segundos que han transcurrido desde la primera marca enviada por el servidor.
Para no complicar más el ejemplo dejaré de lado cuestiones como la resolución de conflictos, aunque es claro que en un escenario real habría que tomarlos en cuenta también.
Otra pequeña licencia que me tomaré será asumir que la primera interacción con el servidor es siempre exitosa.
Para simular la falta de conectividad usaré un botón que permita detener/comenzar la sincronización automática.
En el caso real utilizaría simplemente una verificación de Navigator.online en forma periódica y, al detectar que hay conectividad aprovechar para enviar los eventos que corresponden.
Ajax
La base de este script es la utilización de peticiones asincrónicas (más conocidas como Ajax).
Mediante esta tecnología es posible realizar aplicaciones de tipo single-page (de una sola página).
Se carga una vez un HTML que hace de marco y, a través de JavaScript se manejan las interacciones con el servidor.
LocalStorage
El otro concepto importante sobre el que se basa esta pequeña aplicación es el de almacenamiento local.
Se trata de una característica de los navegadores web modernos que permite almacenar información en formato clave-valor.
Esto me permitirá persistir información del lado del cliente aún en el caso de que la sesión se cierre abruptamente (Por ejemplo por un corte de luz).
Y ahora sí, vamos a ver algo de código 🙂
El código
El backend
Del lado del servidor tendremos un simple archivo php:
Este pequeño servidor se encargará de enviar a cada cliente los eventos que sucedieron luego de una cierta marca de tiempo (Que se supone corresponde con el último evento que el cliente recibió del servidor) en algún otro cliente.
A su vez, tomará los nuevos eventos enviados por el cliente y los incorporará a la base de datos centralizada.
Por último, para el caso especial en que el cliente no haya informado su id se asumirá que se trata de la primera interacción, con lo cual, le será asignado uno.
El frontend
Por el lado del frontend tendremos dos archivos, un HTML:
let clientId = localStorage.getItem('clientId') || '';
let events = JSON.parse(localStorage.getItem('events')) || [];
let nonSynced = JSON.parse(localStorage.getItem('nonSynced')) || [];
let syncEnabled = false;
let initialTime = events.length ? events[events.length - 1].timestamp : 0;
let lastSync = 0;
let elapsed = 0;
let nextLocalId = 1;
document.getElementById('clientId').innerText = clientId;
document.getElementById('syncEnabled').innerText = 'deshabilitada';
document.getElementById('toogleSync').innerText = 'Habilitar';
refreshTable();
window.setInterval(function () {
if (navigator.onLine && clientId && syncEnabled) {
sync();
}
}, 3000);
window.setInterval(function () {
elapsed += 1;
}, 1000);
if ('' == clientId) {
sync();
}
document.getElementById('toogleSync').addEventListener('click', toggleSync);
document.getElementById('newContent').addEventListener('keyup', function (event) {
if ("Enter" == event.code) {
addRecord(this.value, initialTime + elapsed);
this.value = '';
}
});
function toggleSync() {
syncEnabled = !syncEnabled;
if (syncEnabled) {
document.getElementById('syncEnabled').innerText = 'habilitada';
document.getElementById('toogleSync').innerText = 'Deshabilitar';
} else {
document.getElementById('syncEnabled').innerText = 'deshabilitada';
document.getElementById('toogleSync').innerText = 'Habilitar';
}
}
function removeRecord(id) {
let event = events.find(event => event.id == id);
if (nonSynced.find(event => event.id == id)) {
removeAddEvent(event.id);
} else {
addDeleteEvent(event.id);
}
events = events.filter(event => event.id != id);
refreshTable();
}
function addDeleteEvent(id) {
let newEvent = {
action: 'D',
id: id,
timestamp: initialTime + elapsed
};
events.push(newEvent);
nonSynced.push(newEvent);
}
function removeAddEvent(id) {
events = events.filter(event => event.id != id);
nonSynced = nonSynced.filter(event => event.id != id);
localStorage.setItem('events',JSON.stringify(events));
localStorage.setItem('nonSynced',JSON.stringify(nonSynced));
}
function addRecord(value, timestamp, id = null) {
let newEvent = {
'timestamp': timestamp,
'action': 'A',
'contents': value,
'id': id ? id : clientId + '-' + nextLocalId++,
};
if (!id) {
nonSynced.push(newEvent);
localStorage.setItem('nonSynced', JSON.stringify(nonSynced));
}
events.push(newEvent);
localStorage.setItem('events',JSON.stringify(events));
events.sort(function (event1, event2) {
if (event1.timestamp == event2.timestamp) {
return 0;
} else if (event1.timestamp > event2.timestamp) {
return 1;
} else {
return -1;
}
});
refreshTable();
}
function refreshTable() {
let table = document.getElementById('record_table');
let oldBody = table.tBodies[0];
let newBody = document.createElement('tbody');
let addEvents = events.filter(event => 'A' === event.action);
for (let i in addEvents) {
if (events.find(event => 'D' === event.action && addEvents[i].id == event.id)) {
continue;
}
let row = newBody.insertRow();
let cell = document.createElement('td');
cell.innerText = addEvents[i].id;
row.append(cell);
cell = document.createElement('td');
cell.innerText = addEvents[i].timestamp;
row.append(cell);
cell = document.createElement('td');
cell.innerText = addEvents[i].contents;
row.append(cell);
cell = document.createElement('td');
cell.innerHTML = '<button onclick="removeRecord(\'' + addEvents[i].id + '\')">Eliminar</button>';
row.append(cell);
}
table.replaceChild(newBody, oldBody);
}
function addRemoteEvents(newEvents) {
for (let i in newEvents) {
events.push(newEvents[i]);
lastSync = newEvents[i].timestamp;
}
events.sort(function(e1, e2) {
if (e1.timestamp == e2.timestamp) {
return 0;
} else if (e1.timestamp > e2.timestamp) {
return 1;
} else {
return -1;
}
});
localStorage.setItem('events',JSON.stringify(events));
}
function sync() {
var xhttp = new XMLHttpRequest();
document.getElementById('newContent').disabled = true;
xhttp.onreadystatechange = function () {
if (this.readyState == 4 && this.status == 200) {
document.getElementById('newContent').disabled = false;
let response = JSON.parse(this.responseText);
if (!clientId) {
clientId = response.clientId;
localStorage.setItem('clientId', clientId);
document.getElementById('clientId').innerText = clientId;
initialTime = response.timestamp;
document.getElementById('clientInfo').style = 'display: block;';
}
addRemoteEvents(response.newEvents);
refreshTable();
nonSynced = [];
localStorage.setItem('nonSynced', JSON.stringify(nonSynced));
}
};
xhttp.open("POST", "sync.php?lastSync=" + lastSync + "&clientId=" + clientId, true);
xhttp.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
xhttp.send(JSON.stringify(nonSynced));
}
Este último (La parte más interesante) funciona de la siguiente manera:
Lo primero que se intenta es re-establecer el estado recurriendo a lo almacenado en LocalStorage.
Para atacar el problema de la sincronización tomamos un tiempo inicial provisto por el servidor y, cada vez que se produce un evento le sumamos la cantidad de segundos transcurridos en el cliente, de modo de que todos los eventos tengan una misma referencia.
Este algoritmo está lejos de ser perfecto, pero lo uso para ilustrar precisamente el desafío que supone tratar con eventos en forma distribuida.
Constantemente mantengo en memoria una lista de eventos y otra de eventos aún no sincronizados.
De esta forma, los eventos se van encolando mientras la sincronización no está activa y, apenas se detecta conectividad, se envían todas las novedades y se procesan las que los demás clientes han producido.
Esas mismas listas se almacenan en el LocalStorage para prevenir una desincronización por, por ejemplo, una súbita pérdida de energía.
Conclusión
Como puedes ver, darle este tipo de robustez a una aplicación web no es precisamente tarea sencilla
Honestamente, dudo de que haya muchos escenarios reales que lo justifiquen.
Seguramente existen frameworks JavaScript que resuelven estos problemas de una mejor forma, sólo quise mostrarlo en la versión cruda para que queden claras las dificultades por subsanar.
¿Cuál esería una forma segura de autenticar el jwt que llega en la petición?
Ante todo gracias Ezequiel y perdona la tardanza en responder.
Vamos por partes para que se entienda bien de qué estamos hablando.
Qué es JWT
JWT son las siglas de JSON Web Tokens. Se trata de una tecnología desarrollada por la empresa Auth0 cuyo objetivo es la transmisión segura de información a través de una red insegura (Internet).
Como en la mayoría de los mecanismos de seguridad, se trata del envío de información codificada utilizando métodos muy difíciles de descifrar para quien no tenga la información completa pero muy simples para quien sí la posea.
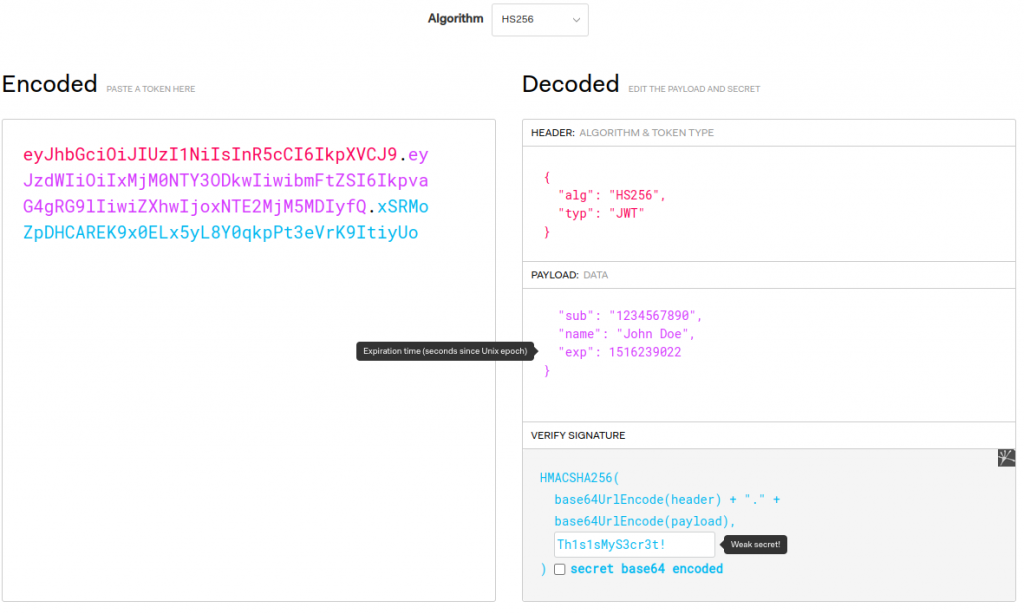
Desde afuera un token JWT es una cadena de caracteres aleatoria, por ejemplo:
En realidad, si la miras con algo más de detenimiento notarás que se trata de una cadena particular formada por tres cadenas unidas por un .
Cuáles son los componentes de un token JWT
Un token JWT está conformado por:
Un encabezado
La carga útil o payload (El mensaje que se busca transmitir)
Una firma
El encabezado indica el algoritmo que se utilizará para realizar la codificación y la posterior verificación.
El payload es una cadena que representa un objeto JSON.
Por último, la firma se utilizará para darle confiabilidad a la transmisión.
Dependiendo del algoritmo utilizado esta cadena puede ser una frase cualquiera o un certificado digital.
Para qué se usa JWT
Existen muchos casos en los que vale la pena utilizar un token JWT. Uno de los usos más comunes es cuando se busca garantizar la identidad de una entidad que requiere hacer uso de un Servicio Web de nuestra propiedad.
En general, este mecanismo se adapta mejor que el uso de sesiones estándar.
Más aún, si la comunicación se realiza entre más de dos actores, JWT ofrece un soporte difícil de lograr con las sesiones.
Una ventaja clara de JWT contra otros tipos de autenticación es el hecho de que los tokens pueden ser verificados sin necesidad de acceder a información externa (Bases de datos por ejemplo).
Un punto muy importante a tener en cuenta cuando se usan tokens JWT es que la información transportada no se encuentra encriptada. Sólo la firma lo está.
Esto permite garantizar que la información transportada no ha sido alterada durante la transmisión, pero no puede garantizar que un agente malicioso la haya leído.
Cómo leer un token JWT usando PHP
En el caso de la pregunta que realiza Ezequiel vale el supuesto de que el token ha sido generado por algún tercero del cual se pretende validar su autenticidad.
Para ello existen, además de la posibilidad de descifrar el token manualmente, una serie de librerías que se detallan en el sitio de Auth0. Dado que se trata de un estándar abierto cualquiera puede crear su propia implementación.
Tomaré como base de este ejemplo este artículo publicado en el propio sitio de Auth0.
El primer paso para trabajar con un token JWT es verificar su autenticidad.
Cómo verificar la autenticidad de un token JWT usando PHP
Para verificar la autenticidad del token se requiere calcular la firma y validarla contra la recibida.
Si coinciden se puede asumir que el mensaje no ha sido alterado por terceros, en caso contrario el token debe ser rechazado.
Podemos realizar esta verificación utilizando este código:
<?php
require 'bootstrap.php';
use Carbon\Carbon;
// get the local secret key
$secret = getenv('SECRET');
if (! isset($argv[1])) {
exit('Please provide a key to verify');
}
$jwt = $argv[1];
// split the token
$tokenParts = explode('.', $jwt);
$header = base64_decode($tokenParts[0]);
$payload = base64_decode($tokenParts[1]);
$signatureProvided = $tokenParts[2];
// check the expiration time - note this will cause an error if there is no 'exp' claim in the token
$expiration = Carbon::createFromTimestamp(json_decode($payload)->exp);
$tokenExpired = (Carbon::now()->diffInSeconds($expiration, false) < 0);
// build a signature based on the header and payload using the secret
$base64UrlHeader = base64UrlEncode($header);
$base64UrlPayload = base64UrlEncode($payload);
$signature = hash_hmac('sha256', $base64UrlHeader . "." . $base64UrlPayload, $secret, true);
$base64UrlSignature = base64UrlEncode($signature);
// verify it matches the signature provided in the token
$signatureValid = ($base64UrlSignature === $signatureProvided);
echo "Header:\n" . $header . "\n";
echo "Payload:\n" . $payload . "\n";
if ($tokenExpired) {
echo "Token has expired.\n";
} else {
echo "Token has not expired yet.\n";
}
if ($signatureValid) {
echo "The signature is valid.\n";
} else {
echo "The signature is NOT valid\n";
}
Para que este código pueda ejecutarse será necesario crear un archivo composer.json con este contenido:
Header:
{"alg":"HS256","typ":"JWT"}
Payload:
{"sub":"1234567890","name":"John Doe","exp":1516239022}
Token has expired.
The signature is valid.
Con lo cual, se ha confirmado la autenticidad del token recibido.
Algunas librerías JWT para PHP
Esta verificación se realizó analizando manualmente el token y, si bien esto es perfectamente posible, no es lo más conveniente en un ambiente de producción (Principalmente por motivos de mantenibilidad a largo plazo).
Algo más recomendable es la utilización de alguna librería.
La tarea de migrar un sitio web no es particularmente sencilla.
Obviamente, no todos los sitios tienen la misma infraestructura, con lo cual, lo que te voy a contar no necesariamente aplica a tu caso, pero espero que te lleves algunas ideas que puedan ayudarte.
Voy a suponer por el momento que tu sitio tiene los componentes típicos:
Una base de datos
Un paquete de código
El hecho de que tu sitio esté online significa que existe, al menos, un servidor donde está alojado.
Y por último, hay un par de componentes muy importantes si el sitio es accesible para todo público:
Supongamos que el servidor donde está la base de datos no es el mismo que donde reside la aplicación, es decir, lo que querés hacer en principio es migrar tu código a algún otro servidor (dentro o fuera del hosting actual).
Mi recomendación es que antes de migrar hagas un relevamiento detallado de qué infraestructura estás usando (y, esperablemente, está funcionando):
¿Qué versión de PHP estás usando? ¿Qué paquetes tiene instalado?
¿Qué tipo de webserver? ¿Qué versión?
¿Qué motor de base de datos? ¿Qué versión?
¿Qué permisos tienen los directorios de la aplicación?
Etc…
Una vez tengas claro este panorama, lo siguiente es armar un plan de pruebas básico que permita detectar rápidamente si algo no quedó 100% bien durante el traspaso.
No hay que hacer mucho acá, sólo saber cuáles son las funcionalidades críticas del sitio y qué experimentos permitirán determinar que están ok.
La estrategia general va a ser clonar tu sitio actual y, por un tiempo lo más breve posible, tener el original y el clon conviviendo lo más armoniosamente que se pueda… y luego matar al clon.
Por qué migrar de servidor
Empecemos pensando en qué razones tendrías para migrar de servidor.
Se me ocurren varias:
Conseguiste uno más barato
El hosting actual no te da el soporte que necesitás
El hardware te quedó chico
O, como le ocurrió a un cliente mío recientemente, el tráfico te superó y tenés que implementar balanceo de carga.
Cómo migrar el código de tu sitio
Migrar el código suele ser la parte más fácil.
Si lo tenés versionado simplemente se trata de hacer un checkout (o un git clone o similar) en tu nuevo servidor.
Si no lo tenés versionado vas a necesitar subirlo de alguna forma… ftp, scp, rsync… la que prefieras.
Una vez tengas el código presente en tu nuevo servidor te va a tocar modificar las configuraciones para dejar andando.
Algo a lo que tenés que prestar atención es que el usuario de tu aplicación esté habilitado para realizar consultas desde la nueva IP (Al menos en el caso de MySQL esto puede ser un problema).
Cómo migrar la configuración de tu sitio
Nuevamente, esto dependerá en gran medida de cómo lo tengas montado actualmente.
Lo ideal sería que la dependencia respecto del webserver sea mínima para evitar problemas de incompatibilidades.
Por ejemplo, algo que suele hacerse con los sitios montados sobre Apache es usar el archivo .htaccess… claramente, si vas a migrar hacia un servidor con NginX la cosa se va a complicar.
Si la configuración no está versionada vas a tener que asegurarte de que el hosting de destino tenga la misma configuración (idealmente) o que las configuraciones del nuevo servidor sean compatibles con tu aplicación.
Cómo migrar un dominio a un nuevo servidor
Acá se trata de cambiar los registros de DNS para que apunten a la IP del nuevo servidor.
En tu servidor de nombres vas a encontrar un registro tipo A que apunta a la IP de tu servidor actual (Y tal vez encuentres uno tipo AAAA con la dirección IPv6).
Cuando cambies ese valor cada vez que alguien escriba http://tusitio.com ingresará al servidor que responda a la nueva IP.
El problema es que los cambios de DNS no son inmediatos (Pueden tomar hasta 48 hs!).
Y otro pequeño problema es cómo probar todo antes de darle al botón rojo.
Un truco que podés usar es hacer el cambio en forma local antes de tocar los DNS.
El tema es simple: tu computadora tiene una serie de definiciones de nombres en un archivo y esa definición toma prioridad sobre cualquier otra información que se encuentre en Internet (Por un tema de optimización principalmente).
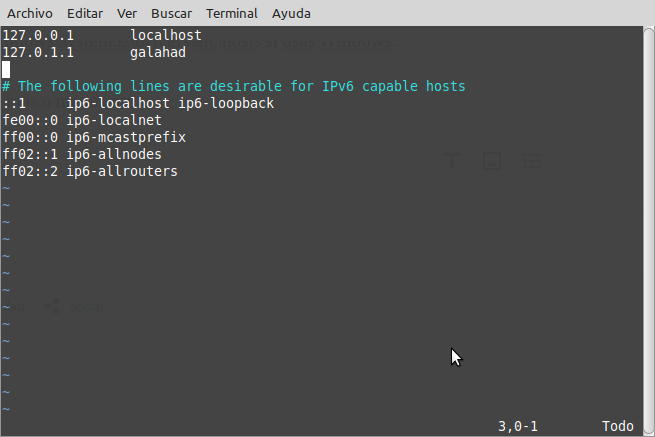
Ese archivo está en /etc/hosts si usás Linux o similar o en C:\Windows\System32\drivers\etc\hosts si usás Windows.
Se ve más o menos así:
Lo que podés hacer es agregar una línea tipo:
XX.YY.ZZ.WW tusitio.com
Y a partir de ahí, cualquier petición que hagas, no importa si es a través de un navegador, cURL o lo que fuera, va a ir a la IP XX.YY.ZZ.WW (No importa lo que diga el DNS).
Una vez hayas hecho todas las pruebas y tengas confianza en que todo está en su lugar podrás efectivizar el cambio de los DNS.
Por precaución te recomiendo no dar de baja el hosting original por un tiempo prudencial (Una semana, un mes… depende qué tan conservador quieras ser) pero claramente la prueba de fuego llegará cuando lo hagas 🙂
En conclusión: no es una magia oculta pero para no tener sorpresas desagradables más vale dedicar algo de tiempo a planificar la mudanza.
Hurgando en las profundidades de la Internet me encontré con una pregunta muy interesante.
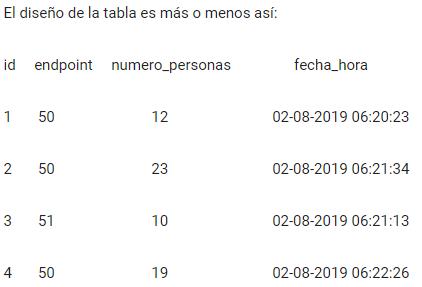
El autor comentaba que tenía una tabla con esta pinta:
Y quería, mediante una consulta a MySQL, obtener un resultado de este tipo:
Básicamente el desafío era transformar datos horizontales (los valores de la columna «endpoint» para cada fila) en verticales, es decir, columnas de la respuesta.
No es algo que se vea todos los días, cierto, pero… ¿cómo rechazar un desafío semejante? 🙂
Inmediatamente me vino a la mente el concepto de Tabla Pivot que manejan las planillas de cálculo.
Así que me arremangué y escribí este SQL:
SELECT FROM_UNIXTIME(FLOOR((UNIX_TIMESTAMP(fecha_hora))/60)*60) as fecha_hora,
SUM(
CASE
WHEN endpoint = 50
THEN numero_personas
ELSE 0
END
) as suma_personas_ep50,
SUM(
CASE
WHEN endpoint = 51
THEN numero_personas
ELSE 0
END
) as suma_personas_ep51
FROM t
GROUP BY FROM_UNIXTIME(FLOOR((UNIX_TIMESTAMP(fecha_hora))/60)*60)
;
Con esto obtuve el resultado esperado. ¡Exito!
Pero… inmediatamente surgió la pregunta en mi cabeza: ¿Qué pasará cuando se agreguen nuevos endpoints?
Pues… ¡usemos un poco de PHP!
<?php
try {
$pdo = new PDO("mysql:dbname=escuelait;host=localhost", "root", "1234");
} catch ( PDOException $e ) {
die ( $e->getMessage() );
}
$sql = "SELECT DISTINCT(endpoint) FROM t;";
$endPoints = $pdo->query($sql, PDO::FETCH_COLUMN,0)->fetchAll();
$templateSQL = "SUM(
CASE
WHEN endpoint = |ENDPOINT|
THEN numero_personas
ELSE 0
END
) as suma_personas_ep|ENDPOINT|";
$endPointsSQL = implode( ",".PHP_EOL, array_map( function( $endPoint ) use ( $templateSQL ) {
return preg_replace( '/\|ENDPOINT\|/', $endPoint, $templateSQL ) ;
}, $endPoints ) );
$finalSQL = "SELECT FROM_UNIXTIME(FLOOR((UNIX_TIMESTAMP(fecha_hora))/60)*60) as fecha_hora,
$endPointsSQL
FROM t
GROUP BY FROM_UNIXTIME(FLOOR((UNIX_TIMESTAMP(fecha_hora))/60)*60)
;";
echo $finalSQL.PHP_EOL;
Este script realiza dos consultas:
La primera para obtener los endpoints existentes
La segunda para generar la tabla dinámica
El truco está en generar el string SQL en forma dinámica.
No es la sintaxis más utilizada pero… puede serte útil alguna vez 😉
Hace tiempo que vengo usando (¡y abogando por su uso!) máquinas virtuales para mis proyectos PHP.
Hasta ahora me venía manejando con Vagrant y debo decir que me ha dado unas cuantas satisfacciones.
Sin embargo, hay algunos problemas derivados de su uso:
Las VM se pueden volver muy pesadas
Ocupan mucho espacio en el disco
Son lentas de levantar
No es sencillo tener muchas corriendo a la par (Consumen muchos recursos de hardware)
No es fácil asegurarme de que en Producción y en Desarrollo tengo exactamente el mismo software instalado.
Investigando un poco y, hay que decirlo también, por consejo de algunos colegas me metí con docker.
Qué es Docker
Docker es una herramienta de virtualización basada en un concepto algo diferente al que usa Vagrant: los contenedores.
No me voy a meter acá en los detalles técnicos, simplemente diré que un contenedor hace un uso mucho más eficiente de los recursos del hardware y, a los fines prácticos, cumple la misma función que una VM.
Cómo se usa Docker
Docker se basa en el docker daemon corriendo constantemente y luego en un cliente que le envía comandos.
Lo primero que necesitás es tener algún contenedor levantado… y para eso, lo primero que necesitás es tener algún contenedor creado.
Los contenedores se crean en base a imágenes.
Qué es una imagen de Docker
Una imagen de docker es una definición de un entorno de ejecución completo (algo así como una VM de Vagrant).
Un contenedor es una imagen en ejecución.
Podrías pensarlo como la diferencia entre un programa y un proceso.
Las imágenes docker se definen en un archivo de texto llamado Dockerfile (Bastante similar al Vagrantfile).
La primera (FROM) es tal vez la más importante: la imagen base.
Las imágenes docker manejan un concepto similar al de la herencia de POO: Sobre una imagen base es posible crear otras más especializadas.
Para efectivamente arrancar esta imagen debemos crear un contenedor basado en ella.
Antes de hacer eso es conveniente crear un archivo llamado your-script.php (Es importante hacerlo antes de crear el contenedor porque el comando COPY se ejecutará durante la creación y no volverá a ejecutarse hasta que el contenedor sea destruido y vuelto a crear).
En cierto sentido, esto es como quemar una ROM 🙂
Pues entonces, creemos un archivo your-script.php con este contenido:
<?php
echo "Estoy en docker!!".PHP_EOL;
Y ahora sí ¡estamos listos para darle vida a nuestro primer contenedor docker!
sudo docker build -t my-php-app .
Con este comando hemos creado nuestro contenedor.
Para ejecutar algún comando dentro de él usaremos:
sudo docker run -it --rm --name my-running-app my-php-app
Y obtendremos la salida:
Estoy en docker!!
Cómo correr una aplicación web PHP en docker
Típicamente para ejecutar una aplicación web PHP vas a necesitar al menos un servidor web y el intérprete de PHP instalado.
Podrías definir tu propia imagen instalando todos los paquetes y demás, pero… ¿vale realmente la pena?
No.
Puedes basar tu imagen en una que ya tenga un poco más allanado el camino.
Por ejemplo php:7.3-apache está basada en Ubutu 18.04 y ya trae php 7.3, Apache y algún par de utilidades más.
De modo que usando un Dockerfile como este:
FROM php:7.3-apache
COPY . /var/www/html/
Podremos tener un contenedor que incluya un Apache y nuestro código en el DocumentRoot.
Un detalle importante que falta es «avisar» a docker que queremos que nuestro contenedor pueda ser accedido desde afuera a través del puerto 80 (Muy parecido al mapeo de puertos que se usa en Vagrant).
Para eso vamos a usar el comando EXPOSE. El Dockerfile se verá así:
FROM php:7.3-apache
COPY . /var/www/html/
EXPOSE 80
Para no complicar mucho las cosas renombremos el archivo your-script.php a index.php y usemos este comando para crear nuestro contenedor:
sudo docker build -t my-php-web-app .
Para entrar a ver nuestro flamante sitio tenemos que ejecutar:
sudo docker run -p 80:80 --rm -it --name my-web-app my-php-web-app:latest
Y, por supuesto, abrir un navegador en http://localhost.
Si todo salió bien deberías ver algo como:
Cómo desplegar una imagen Docker en Producción
Muy bien, ya tenemos todo casi listo, sólo nos falta ver cómo desplegar nuestra imagen en un servidor de producción y concluimos.
Claramente, esta es la parte que realmente hace una diferencia respecto de usar Vagrant… difícilmente vas a querer montar una VM en un servidor productivo por cada aplicación que tengas… o vas a tener una factura bien abultada en AWS.
Existen varias opciones para realizar el despliegue. Para mantener este artículo dentro de un alcance acotado me voy a limitar a la que considero requiere menos conocimientos extra:
Y listo! Ahora se puede acceder a la aplicación entrando a la dirección pública del servidor y el puerto 8888 (Y si es tu única webapp podrías directamente mapear el puerto 80 de tu servidor al del contenedor).