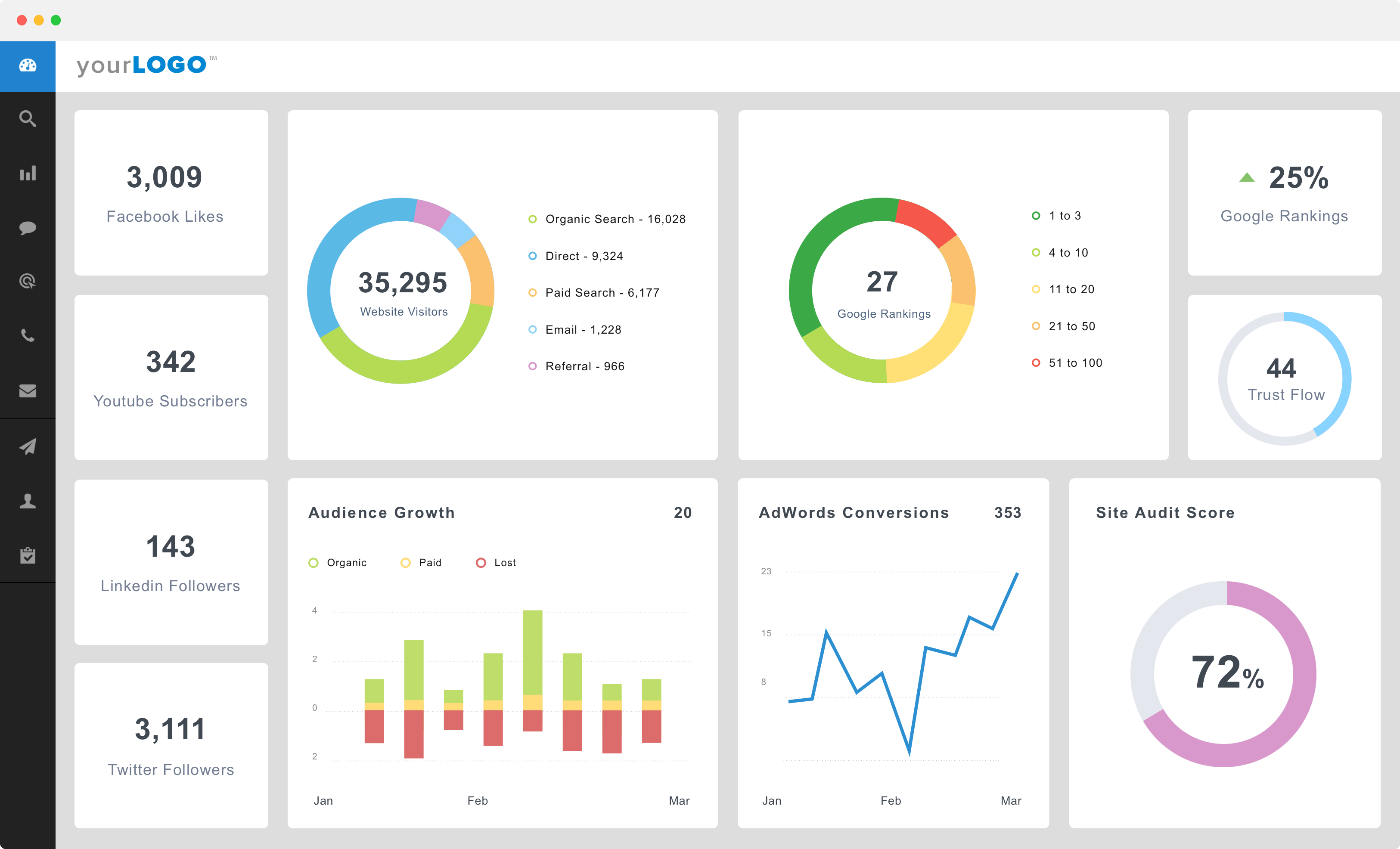
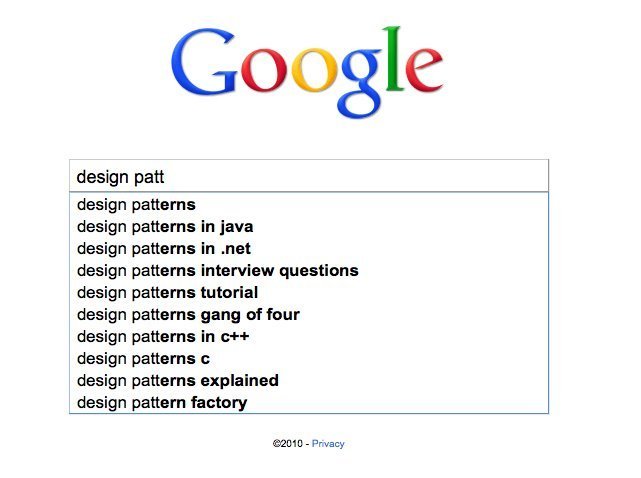
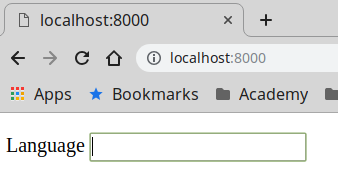
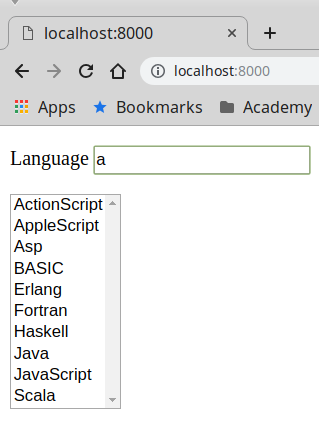
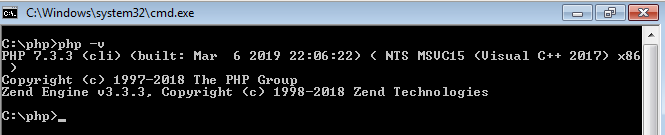
Un lector de mi libro sobre Programación Orientada a Objetos con PHP me envía esta pregunta a través de LinkedIn:

Empecé a responderle a su mensaje pero luego se me ocurrió que sería mejor aprovechar y contestarlo en público así que aquí voy.
Empecemos por comprender de qué se trata cada uno.
Qué es una clase abstracta
En su definición más cruda una clase se dice abstracta si no es posible utilizarla para crear objetos (instancias).
Suena un poco raro, ¿no? ¿Para qué quiero tener una clase si no es para crear instancias?
La explicación viene asociada al concepto de Herencia (Tema para otro artículo en todo caso).
Una clase abstracta puede usarse como base de una jerarquía.
Se define de esta forma:
<?php
abstract class Abstracta
{
public function metodoConcreto()
{
return true;
}
abstract public function metodoAbstracto();
}
Notá cómo el método metodoConcreto() tiene definición (está el cuerpo completo) y como en cambio, de metodoAbstracto() sólo está su declaración (Aparte de llevar la palabra «abstract» como modificador).
Para usarla en una clase concreta se necesita que la hija complete las definiciones que su padre (o alguno de sus ancestros) han dejado inconclusas:
class Concreta extends Abstracta
{
public function metodoAbstracto()
{
return true;
}
}
En la vida real, este tipo de estructura viene muy bien para implementar, por ejemplo, hooks.
La idea será algo como esto: la clase padre (abstracta) define una serie de operaciones bastante complejas y repetitivas y deja una o dos funciones sin definir para que la clase hija escriba aquí sus particularidades.
Un ejemplo que me viene a la mente es un ORM basado en ActiveRecord.
En este caso, habría una clase Record que tendría un método save y podría tener algún método tipo preSave/postSave para que cada tipo de registro en particular pueda intercalar validaciones u operaciones encadenadas.
Qué es una interface
Una interface puede definirse como una declaración de métodos abstractos.
En este sentido se parece a una clase abstracta… la diferencia (a simple vista al menos) es que una interface no puede definir métodos (Sólo puede declararlos).
Se ve de esta forma:
interface UnaInterface
{
public function f1();
public function f2();
}
Según los teóricos más puristas de la Programación Orientada a Objetos toda clase debería implementar al menos una interface.
Por lo general se utilizan interfaces cuando se quiere unificar nombres de métodos pero seguir manteniendo comportamientos que no tienen nada que ver uno con el otro.
De hecho, las interfaces suelen utilizarse como factor común entre clases que no pertenencen a una misma jerarquía.
Por ejemplo, si tomamos una clase Book y otra clase Invoice sería difícil establecer una relación jerárquica entre ellas (Ni Book es un tipo especial de Invoice ni viceversa).
Sin embargo, es muy probable que ambas clases se beneficien de contar con un método print, aunque la forma específica de responder a esa llamada (Es decir, la forma de imprimir) será muy diferente para cada uno de ellos.
Habiendo clases abstractas… ¿por qué se necesitan interfaces?
La respuesta a esta pregunta tiene que ver con algunos problemas de implementación.
En algunos lenguajes (C++ por ejemplo) existe lo que se conoce como Herencia Múltiple (La posibilidad de que una clase tenga más de un antecesor directo).
Es decir, el esquema se vería algo como:

Se ve que la clase TA hereda de Student Y de Faculty. Hasta ahí no hay problema… pero ¿qué pasa si Student define un método con el mismo nombre que Faculty?
Cuando se invoque $ta->metodo() ¿cuál debería ejecutarse? (asumiendo por supuesto que TA no tiene una definición propia de ese método).
Una forma elegante de resolver este problema es impedir la herencia múltiple (Eso es lo que hacen, entre otros, Java y PHP).
Pero la necesidad de reutilizar nombres (y comportamientos) a lo largo de diferentes jerarquías de clases no desaparece… de ahí surge la idea de las interfaces (y los traits… tema para otro artículo).
Un punto importante: una clase (en PHP al menos) puede implementar tantas interfaces como se desee (pero sólo puede extender una clase base).
Cómo decidir si conviene una clase abstracta o una interface
Pues bien, ahora sí estamos listos para responder a la pregunta original 🙂
Debe usarse una clase abstracta cuando se está modelando una jerarquía de clases y una interface cuando se pretende homogeneizar nombres entre objetos que no están emparentados. Compartir en XEsto parece una obviedad, pero no es tan así… a veces nos encontramos con objetos que parecen estar relacionados mediante herencia pero en realidad no es así.
Para determinar si este es el caso vale preguntarse: «¿Es este objeto un caso particular de sus predecesores?» (Un auto es un vehículo).
El uso de interfaces nos permite «olvidar» momentáneamente con qué tipo de objetos estoy trabajando.
En esto se basa el principio de segregación de la interface (La I de SOLID)
Un ejemplo que me viene a la mente es algo que utilizamos hace unos años para una red social de viajes en la que trabajaba.
Originalmente esta red social permitía a sus usuarios subir sus fotos y diarios de viaje (compartir sus experiencias en formato similar a un blog).
Una foto y un diario de viaje tenían bastante pocas similitudes (De hecho las clases que las representaban no tenían ningún ancestro en común).
Un día surgió la necesidad de dotar al sistema de la posibilidad de que otros usuarios dejaran sus opiniones sobre las fotos y/o los diarios de los demás.
Entonces se nos ocurrió agregarle a la clase usuario un método opinar().
Pero no podíamos crear un método opinarSobreFoto( Foto $foto ) y otro opinarSobreDiario( Diario $diario )… en rigor de verdad podríamos haberlo hecho pero no era para nada mantenible.
Una forma mejor de resolverlo fue crear una interface Opinable que tanto la clase Foto como la clase Diario implementaran y luego el método Usuario::opinar pudiera usar, dando lugar a algo como:
<?php
class Usuario
{
public function opinar( Opinable $opinable, string $texto )
{
return new Opinion( $opinable, $this, $texto );
}
}
De esta forma, agregar otro opinable (Por ejemplo, un destino visitado) no supone ningún problema para la clase Usuario.
Y así todos felices 🙂